Как улучшить random forest
Случайный лес (Random forest, RF) — это алгоритм обучения с учителем. Его можно применять как для классификации, так и для регрессии. Также это наиболее гибкий и простой в использовании алгоритм. Лес состоит из деревьев. Говорят, что чем больше деревьев в лесу, тем он крепче. RF создает деревья решений для случайно выбранных семплов данных, получает прогноз от каждого дерева и выбирает наилучшее решение посредством голосования. Он также предоставляет довольно эффективный критерий важности показателей (признаков).
Случайный лес имеет множество применений, таких как механизмы рекомендаций, классификация изображений и отбор признаков. Его можно использовать для классификации добросовестных соискателей кредита, выявления мошенничества и прогнозирования заболеваний. Он лежит в основе алгоритма Борута, который определяет наиболее значимые показатели датасета.
1. Импорт данных
Для начала загрузим данные и создадим датафрейм Pandas. Так как мы пользуемся предварительно очищенным «игрушечным» набором данных из Scikit-learn, то после этого мы уже сможем приступить к процессу моделирования. Но даже при использовании подобных данных рекомендуется всегда начинать работу, проведя предварительный анализ данных с использованием следующих команд, применяемых к датафрейму ( df ):
- df.head() — чтобы взглянуть на новый датафрейм и понять, выглядит ли он так, как ожидается.
- df.info() — чтобы выяснить особенности типов данных и содержимого столбцов. Возможно, перед продолжением работы понадобится произвести преобразование типов данных.
- df.isna() — чтобы убедиться в том, что в данных нет значений NaN . Соответствующие значения, если они есть, может понадобиться как-то обработать, или, если нужно, может понадобиться убрать целые строки из датафрейма.
- df.describe() — чтобы выяснить минимальные, максимальные, средние значения показателей в столбцах, чтобы узнать показатели среднеквадратического и вероятного отклонения по столбцам.

Фрагмент датафрейма с данными по раку груди. Каждая строка содержит результаты наблюдений за пациентом. Последний столбец, cancer, содержит целевую переменную, которую мы пытаемся предсказать. 0 означает «отсутствие заболевания». 1 — «наличие заболевания»
6. Обучение базовой RF-модели после применения к данным метода главных компонент (модель №2, RF + PCA)
Теперь мы можем передать в ещё одну базовую RF-модель данные X_train_scaled_pca и y_train и можем узнать о том, есть ли улучшения в точности предсказаний, выдаваемых моделью.
Модели сравним ниже.
9. Оценка качества работы моделей на проверочных данных
Теперь можно оценить созданные модели на проверочных данных. А именно, речь идёт о тех трёх моделях, описанных в самом начале материала.
Проверим эти модели:
Создадим матрицы ошибок для моделей и узнаем о том, как хорошо каждая из них способна предсказывать рак груди:

Результаты работы трёх моделей
Здесь оценивается метрика «полнота» (recall). Дело в том, что мы имеем дело с диагнозом рака. Поэтому нас чрезвычайно интересует минимизация ложноотрицательных прогнозов, выдаваемых моделями.
Учитывая это, можно сделать вывод о том, что базовая RF-модель дала наилучшие результаты. Её показатель полноты составил 94.97%. В проверочном наборе данных была запись о 179 пациентах, у которых есть рак. Модель нашла 170 из них.
Порядок действий в алгоритме
- Загрузите ваши данные.
- В заданном наборе данных определите случайную выборку.
- Далее алгоритм построит по выборке дерево решений.
- Дерево строится, пока в каждом листе не более n объектов, или пока не будет достигнута определенная высота.
- Затем будет получен результат прогнозирования из каждого дерева решений.
- На этом этапе голосование будет проводиться для каждого прогнозируемого результата: мы выбираем лучший признак, делаем разбиение в дереве по нему и повторяем этот пункт до исчерпания выборки.
- В конце выбирается результат прогноза с наибольшим количеством голосов. Это и есть окончательный результат прогнозирования.
Random Forest, метод главных компонент и оптимизация гиперпараметров: пример решения задачи классификации на Python
У специалистов по обработке и анализу данных есть множество средств для создания классификационных моделей. Один из самых популярных и надёжных методов разработки таких моделей заключается в использовании алгоритма «случайный лес» (Random Forest, RF). Для того чтобы попытаться улучшить показатели модели, построенной с использованием алгоритма RF, можно воспользоваться оптимизацией гиперпараметров модели (Hyperparameter Tuning, HT).

Кроме того, распространён подход, в соответствии с которым данные, перед их передачей в модель, обрабатывают с помощью метода главных компонент (Principal Component Analysis, PCA). Но стоит ли вообще этим пользоваться? Разве основная цель алгоритма RF заключается не в том, чтобы помочь аналитику интерпретировать важность признаков?
Да, применение алгоритма PCA может привести к небольшому усложнению интерпретации каждого «признака» при анализе «важности признаков» RF-модели. Однако алгоритм PCA производит уменьшение размерности пространства признаков, что может привести к уменьшению количества признаков, которые нужно обработать RF-моделью. Обратите внимание на то, что объёмность вычислений — это один из основных минусов алгоритма «случайный лес» (то есть — выполнение модели может занять немало времени). Применение алгоритма PCA может стать весьма важной частью моделирования, особенно в тех случаях, когда работают с сотнями или даже с тысячами признаков. В результате, если самое важное — это просто создать наиболее эффективную модель, и при этом можно пожертвовать точностью определения важности признаков, тогда PCA, вполне возможно, стоит попробовать.
Теперь — к делу. Мы будем работать с набором данных по раку груди — Scikit-learn «breast cancer». Мы создадим три модели и сравним их эффективность. А именно, речь идёт о следующих моделях:
- Базовая модель, основанная на алгоритме RF (будем сокращённо называть эту модель RF).
- Та же модель, что и №1, но такая, в которой применяется уменьшение размерности пространства признаков с помощью метода главных компонент (RF + PCA).
- Такая же модель, как и №2, но построенная с применением оптимизации гиперпараметров (RF + PCA + HT).
Реализация алгоритма Random Forest
Реализуем алгоритм на простом примере для задачи классификации, используя библиотеку scikit-learn:
Работаем с алгоритмом по стандартному порядку действий, принятому в scikit-learn. Вычисляем AUC-ROC (площадь под кривой ошибок) для тренировочной и тестовой частей модели, чтобы определить ее качество:
4. Обучение базовой модели (модель №1, RF)
Сейчас создадим модель №1. В ней, напомним, применяется только алгоритм Random Forest. Она использует все признаки и настроена с использованием значений, задаваемых по умолчанию (подробности об этих настройках можно найти в документации к sklearn.ensemble.RandomForestClassifier). Сначала инициализируем модель. После этого обучим её на масштабированных данных. Точность модели можно измерить на учебных данных:
Если нам интересно узнать о том, какие признаки являются самыми важными для RF-модели в деле предсказания рака груди, мы можем визуализировать и квантифицировать показатели важности признаков, обратившись к атрибуту feature_importances_ :
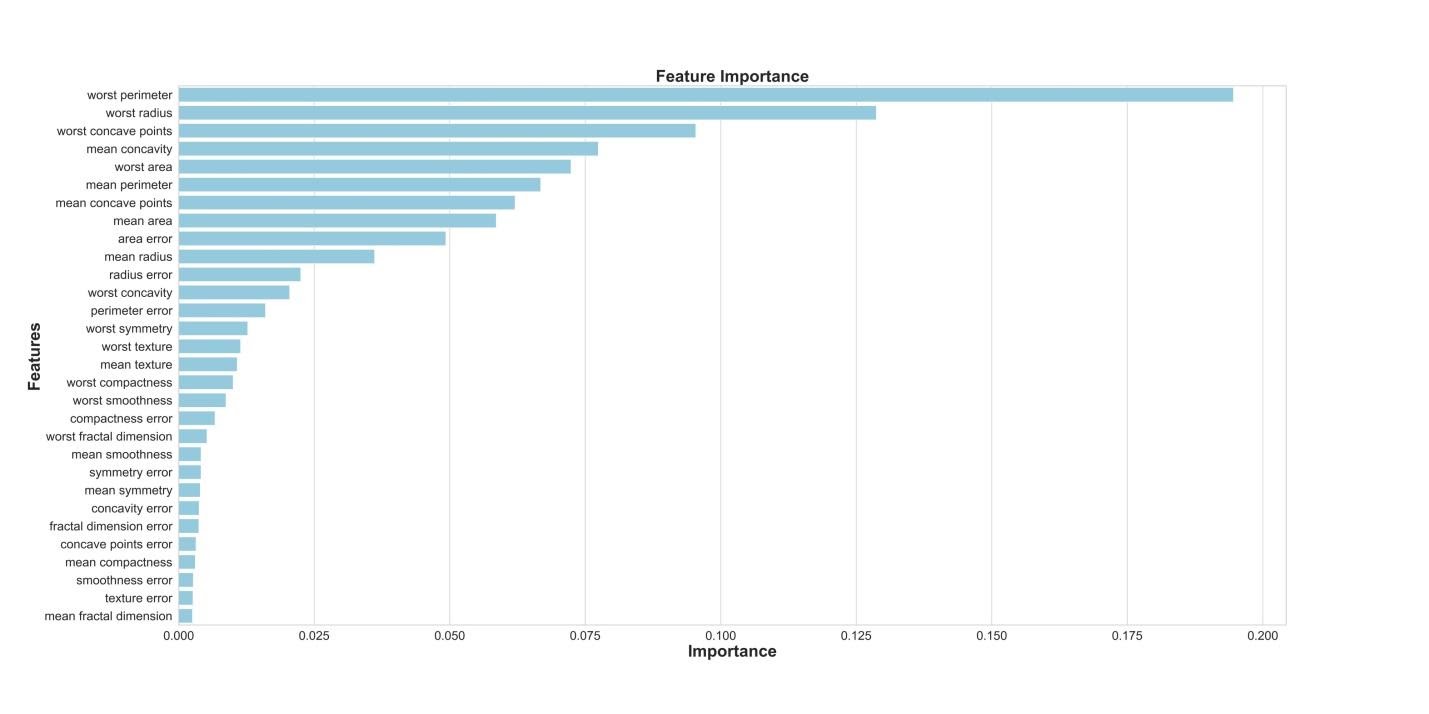
Визуализация «важности» признаков

Показатели важности признаков
Теоретическая составляющая алгоритма случайного дерева
По сравнению с другими методами машинного обучения, теоретическая часть алгоритма Random Forest проста. У нас нет большого объема теории, необходима только формула итогового классификатора a(x) :

- N – количество деревьев;
- i – счетчик для деревьев;
- b – решающее дерево;
- x – сгенерированная нами на основе данных выборка.
Стоит также отметить, что для задачи классификации мы выбираем решение голосованием по большинству, а в задаче регрессии – средним.
Как работает случайный лес?
Алгоритм состоит из четырех этапов:
- Создайте случайные выборки из заданного набора данных.
- Для каждой выборки постройте дерево решений и получите результат предсказания, используя данное дерево.
- Проведите голосование за каждый полученный прогноз.
- Выберите предсказание с наибольшим количеством голосов в качестве окончательного результата.

Поиск важных признаков
Random forest также предлагает хороший критерий отбора признаков. Scikit-learn предоставляет дополнительную переменную при использовании модели случайного леса, которая показывает относительную важность, то есть вклад каждого показателя в прогноз. Библиотека автоматически вычисляет оценку релевантности каждого признака на этапе обучения. Затем полученное значение нормализируется так, чтобы сумма всех оценок равнялась 1.
Такая оценка поможет выбрать наиболее значимые показатели и отбросить наименее важные для построения модели.
Случайный лес использует критерий Джини, также известный как среднее уменьшение неопределенности (MDI), для расчета важности каждого признака. Кроме того, критерий Джини иногда называют общим уменьшением неопределенности в узлах. Он показывает, насколько снижается точность модели, когда вы отбрасываете переменную. Чем больше уменьшение, тем значительнее отброшенный признак. Таким образом, среднее уменьшение является необходимым параметром для выбора переменной. Также с помощью данного критерия можете быть отображена общая описательная способность признаков.
Сравнение случайных лесов и деревьев решений
- Случайный лес — это набор из множества деревьев решений.
- Глубокие деревья решений могут страдать от переобучения, но случайный лес предотвращает переобучение, создавая деревья на случайных выборках.
- Деревья решений вычислительно быстрее, чем случайные леса.
- Случайный лес сложно интерпретировать, а дерево решений легко интерпретировать и преобразовать в правила.
Необходимые параметры алгоритма
Число деревьев – n_estimators
Чем больше деревьев, тем лучше качество. Стоит отметить, что время настройки и работы Random Forest будут пропорционально увеличиваться, что может сказаться на производительности.Часто при большом увеличении n_estimators качество на обучающей выборке может даже доходить до 100%, в то время как качество на тесте выходит на асимптоту , что сигнализирует о переобучении нашей модели. Лучший способ избежать этого – прикинуть, сколько деревьев вам достаточно, зафиксировав момент, когда качество теста еще не становится стабильно-неизменным.
Критерий расщепления – criterion
Также один из самых важных параметров для построения, но без значительной возможности выбора. В библиотеке sklearn для задач классификации реализованы критерии gini и entropy . Они соответствуют классическим критериям расщепления: джини и энтропии.В свою очередь, для задач регрессии реализованы два критерия ( mse и mae ), которые являются функциями ошибок Mean Square Error и Mean Absolute Error соответственно. Практически во всех задачах используется критерий mse .
Простой метод перебора поможет выбрать, что использовать для решения конкретной проблемы.
Число признаков для выбора расщепления – max_features
При увеличении max_features увеличивается время построения леса, а деревья становятся похожими друг на друга. В задачах классификации он по умолчанию равен sqrt(n) , в задачах регрессии – n/3 .
Является одним из самых важных параметров в алгоритме. Он настраивается в первую очередь, после того, как мы определили тип нашей задачи.Минимальное число объектов для расщепления – min_samples_split
Второстепенный по своему значению параметр, его можно оставить в состоянии по умолчанию.
Ограничение числа объектов в листьях – min_samples_leaf
Аналогично с min_samples_split , но при увеличении данного параметра качество модели на обучении падает, в то время как время построения модели сокращается.
Максимальная глубина деревьев – max_depth
Чем меньше максимальная глубина, тем быстрее строится и работает алгоритм случайного дерева.
При увеличении глубины резко возрастает качество как на обучении модели, так и на ее тестировании. Если у вас есть возможность и время для построения глубоких деревьев, то рекомендуется использовать максимальное значение данного параметра.Неглубокие деревья рекомендуется использовать в задачах со значительным количеством шумовых объектов (выбросов).
Заключение
Метод случайного дерева (Random Forest) – это универсальный алгоритм машинного обучения с учителем. Его можно использовать во множестве задач, но в основном он применяется в проблемах классификации и регрессии.
Действенный и простой в понимании, алгоритм имеет значительный недостаток – заметное замедление работы при определенной настройке параметров внутри него.Вы можете использовать случайный лес, если вам нужны чрезвычайно точные результаты или у вас есть огромный объем данных для обработки, и вам нужен достаточно сильный алгоритм, который позволит вам эффективно обработать все данные.
7. Оптимизация гиперпараметров. Раунд 1: RandomizedSearchCV
После обработки данных с использованием метода главных компонент можно попытаться воспользоваться оптимизацией гиперпараметров модели для того чтобы улучшить качество предсказаний, выдаваемых RF-моделью. Гиперпараметры можно рассматривать как что-то вроде «настроек» модели. Настройки, которые отлично подходят для одного набора данных, для другого не подойдут — поэтому и нужно заниматься их оптимизацией.
Начать можно с алгоритма RandomizedSearchCV, который позволяет довольно грубо исследовать широкие диапазоны значений. Описания всех гиперпараметров для RF-моделей можно найти здесь.
В ходе работы мы генерируем сущность param_dist , содержащую, для каждого гиперпараметра, диапазон значений, которые нужно испытать. Далее, мы инициализируем объект rs с помощью функции RandomizedSearchCV() , передавая ей RF-модель, param_dist , число итераций и число кросс-валидаций, которые нужно выполнить.
Гиперпараметр verbose позволяет управлять объёмом информации, который выводится моделью в ходе её работы (наподобие вывода сведений в процессе обучения модели). Гиперпараметр n_jobs позволяет указывать то, сколько процессорных ядер нужно использовать для обеспечения работы модели. Установка n_jobs в значение -1 приведёт к более быстрой работе модели, так как при этом будут использоваться все ядра процессора.
Мы будем заниматься подбором следующих гиперпараметров:
- n_estimators — число «деревьев» в «случайном лесу».
- max_features — число признаков для выбора расщепления.
- max_depth — максимальная глубина деревьев.
- min_samples_split — минимальное число объектов, необходимое для того, чтобы узел дерева мог бы расщепиться.
- min_samples_leaf — минимальное число объектов в листьях.
- bootstrap — использование для построения деревьев подвыборки с возвращением.
При значениях параметров n_iter = 100 и cv = 3 , мы создали 300 RF-моделей, случайно выбирая комбинации представленных выше гиперпараметров. Мы можем обратиться к атрибуту best_params_ для получения сведений о наборе параметров, позволяющем создать самую лучшую модель. Но на данной стадии это может не дать нам наиболее интересных данных о диапазонах параметров, которые стоит изучить на следующем раунде оптимизации. Для того чтобы выяснить то, в каком диапазоне значений стоит продолжать поиск, мы легко можем получить датафрейм, содержащий результаты работы алгоритма RandomizedSearchCV.

Результаты работы алгоритма RandomizedSearchCV
Теперь создадим столбчатые графики, на которых, по оси Х, расположены значения гиперпараметров, а по оси Y — средние значения, показываемые моделями. Это позволит понять то, какие значения гиперпараметров, в среднем, лучше всего себя показывают.
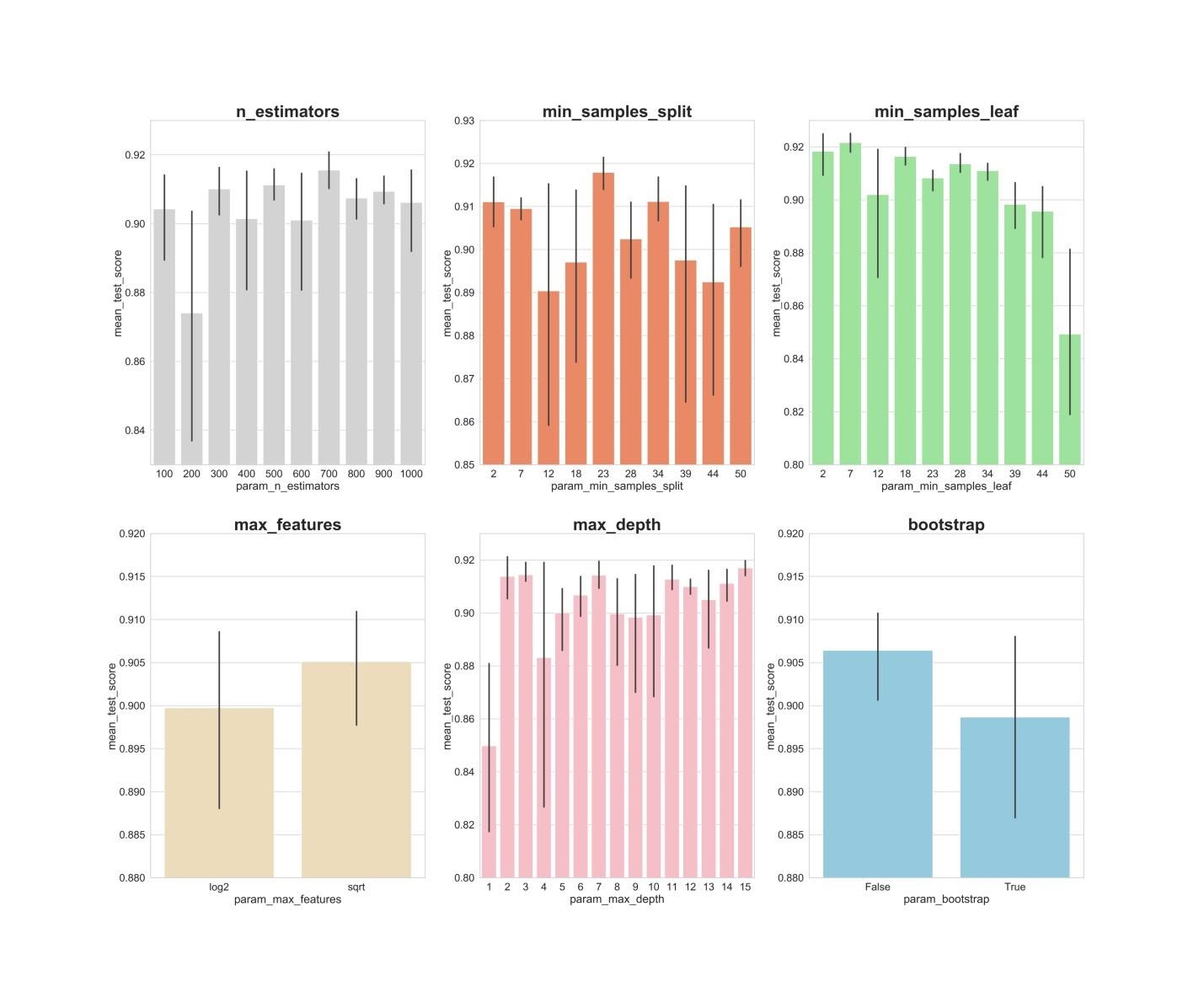
Анализ значений гиперпараметров
Если проанализировать вышеприведённые графики, то можно заметить некоторые интересные вещи, говорящие о том, как, в среднем, каждое значение гиперпараметра влияет на модель.
- n_estimators : значения 300, 500, 700, видимо, показывают наилучшие средние результаты.
- min_samples_split : маленькие значения, вроде 2 и 7, как кажется, показывают наилучшие результаты. Хорошо выглядит и значение 23. Можно исследовать несколько значений этого гиперпараметра, превышающих 2, а также — несколько значений около 23.
- min_samples_leaf : возникает такое ощущение, что маленькие значения этого гиперпараметра дают более высокие результаты. А это значит, что мы можем испытать значения между 2 и 7.
- max_features : вариант sqrt даёт самый высокий средний результат.
- max_depth : тут чёткой зависимости между значением гиперпараметра и результатом работы модели не видно, но есть ощущение, что значения 2, 3, 7, 11, 15 выглядят неплохо.
- bootstrap : значение False показывает наилучший средний результат.
5. Метод главных компонент
Теперь зададимся вопросом о том, как можно улучшить базовую RF-модель. С использованием методики снижения размерности пространства признаков можно представить исходный набор данных через меньшее количество переменных и при этом снизить объём вычислительных ресурсов, необходимых для обеспечения работы модели. Используя PCA, можно изучить кумулятивную выборочную дисперсию этих признаков для того чтобы понять то, какие признаки объясняют большую часть дисперсии в данных.
Инициализируем объект PCA ( pca_test ), указывая количество компонент (признаков), которые нужно рассмотреть. Мы устанавливаем этот показатель в 30 для того чтобы увидеть объяснённую дисперсию всех сгенерированных компонент до того, как примем решение о том, сколько компонент нам понадобится. Затем передаём в pca_test масштабированные данные X_train , пользуясь методом pca_test.fit() . После этого визуализируем данные.
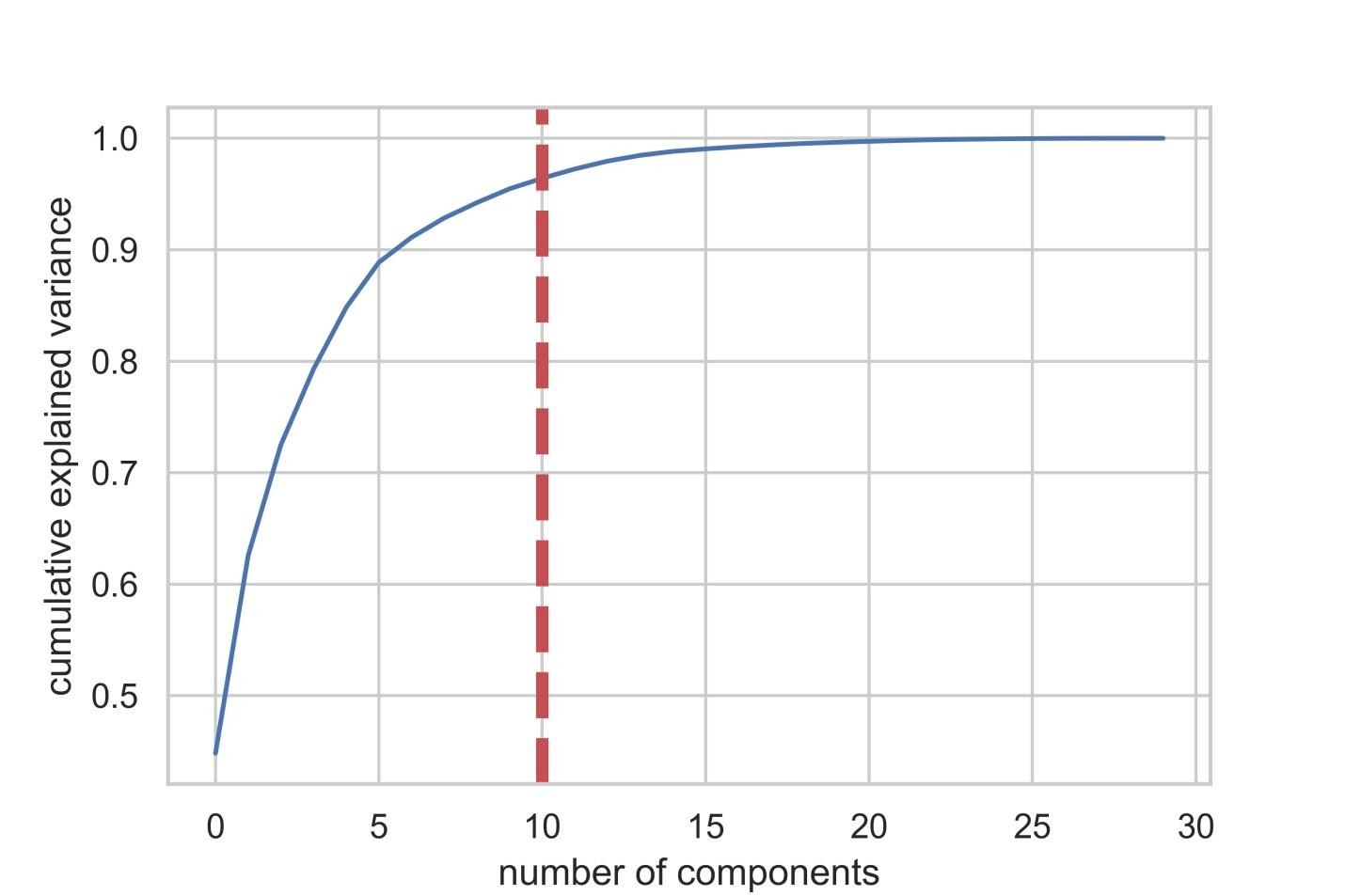
После того, как число используемых компонент превышает 10, рост их количества не очень сильно повышает объяснённую дисперсию

Этот датафрейм содержит такие показатели, как Cumulative Variance Ratio (кумулятивный размер объяснённой дисперсии данных) и Explained Variance Ratio (вклад каждой компоненты в общий объём объяснённой дисперсии)
Если взглянуть на вышеприведённый датафрейм, то окажется, что использование PCA для перехода от 30 переменных к 10 компонентам позволяет объяснить 95% дисперсии данных. Другие 20 компонент объясняют менее 5% дисперсии, а это значит, что от них мы можем отказаться. Следуя этой логике, воспользуемся PCA для уменьшения числа компонент с 30 до 10 для X_train и X_test . Запишем эти искусственно созданные наборы данных «пониженной размерности» в X_train_scaled_pca и в X_test_scaled_pca .
Каждая компонента — это линейная комбинация исходных переменных с соответствующими «весами». Мы можем видеть эти «веса» для каждой компоненты, создав датафрейм.

Датафрейм со сведениями по компонентам
? Машинное обучение для начинающих: алгоритм случайного леса (Random Forest)

Благодаря своей гибкости Random Forest применяется для решения практически любых проблем в области машинного обучения. Сюда относятся классификации (RandomForestClassifier) и регрессии (RandomForestRegressor), а также более сложные задачи, вроде отбора признаков, поиска выбросов/аномалий и кластеризации.
Основным полем для применения алгоритма случайного дерева являются первые два пункта, решение других задач строится уже на их основе. Так, для задачи отбора признаков мы осуществляем следующий код:
Здесь мы на основе классификации просто добавляем метод для отбора признаков.
3. Масштабирование данных
Прежде чем приступать к моделированию, нужно выполнить «центровку» и «стандартизацию» данных путём их масштабирования. Масштабирование выполняется из-за того, что разные величины выражены в разных единицах измерения. Эта процедура позволяет организовать «честную схватку» между признаками при определении их важности. Кроме того, мы конвертируем y_train из типа данных Pandas Series в массив NumPy для того чтобы позже модель смогла бы работать с соответствующими целевыми показателями.
8. Оптимизация гиперпараметров. Раунд 2: GridSearchCV (окончательная подготовка параметров для модели №3, RF + PCA + HT)
После применения алгоритма RandomizedSearchCV воспользуемся алгоритмом GridSearchCV для проведения более точного поиска наилучшей комбинации гиперпараметров. Здесь исследуются те же гиперпараметры, но теперь мы применяем более «обстоятельный» поиск их наилучшей комбинации. При использовании алгоритма GridSearchCV исследуется каждая комбинация гиперпараметров. Это требует гораздо больших вычислительных ресурсов, чем использование алгоритма RandomizedSearchCV, когда мы самостоятельно задаём число итераций поиска. Например, исследование 10 значений для каждого из 6 гиперпараметров с кросс-валидацией по 3 блокам потребует 10? x 3, или 3000000 сеансов обучения модели. Именно поэтому мы и используем алгоритм GridSearchCV после того, как, применив RandomizedSearchCV, сузили диапазоны значений исследуемых параметров.
Итак, используя то, что мы выяснили с помощью RandomizedSearchCV, исследуем значения гиперпараметров, которые лучше всего себя показали:
Здесь мы применяем кросс-валидацию по 3 блокам для 540 (3 x 1 x 5 x 6 x 6 x 1) сеансов обучения модели, что даёт 1620 сеансов обучения модели. И уже теперь, после того, как мы воспользовались RandomizedSearchCV и GridSearchCV, мы можем обратиться к атрибуту best_params_ для того чтобы узнать о том, какие значения гиперпараметров позволяют модели наилучшим образом работать с исследуемым набором данных (эти значения можно видеть в нижней части предыдущего блока кода). Эти параметры используются при создании модели №3.
Итоги
Это исследование позволяет сделать важное наблюдение. Иногда RF-модель, в которой используется метод главных компонент и широкомасштабная оптимизация гиперпараметров, может работать не так хорошо, как самая обыкновенная модель со стандартными настройками. Но это — не повод для того, чтобы ограничивать себя лишь простейшими моделями. Не попробовав разные модели, нельзя сказать о том, какая из них покажет наилучший результат. А в случае с моделями, которые используются для предсказания наличия у пациентов рака, можно сказать, что чем лучше модель — тем больше жизней может быть спасено.
2 ответа
Кажется, вы пытались настроить гиперпараметр. Что заставляет вас думать, что вы можете достичь точности выше 78%? Если вы вычисляете балл точности при попытке прогнозирования на тренировочном наборе, вы достигаете почти 100% точности? Если это так, то это проблема переоснащения , и вы можете попытаться уменьшить количество деревьев в вашем RandomForest.
Если вы не получаете очень высокую точность обучения, то, возможно, имеющиеся у вас функции недостаточно хороши для прогнозирования данных, и вы можете рассмотреть возможность сбора дополнительных функций. Эта проблема называется недостаточное оснащение .
Вы пытались использовать настройку гиперпараметра, если не пытаетесь использовать GridSearchCV или RandomizedSearchCV из sklearn. Даже в этом случае, если вы не можете улучшить оценку своей модели, попробуйте использовать XGboost или выполнить разработку функций, чтобы найти полезные функции для прогнозирования.
Я надеюсь, что вы сделали всю необходимую предварительную обработку данных, если не сделаете их, которые очень важны. Попробуйте другие модели машинного обучения, также есть вероятность, что они могут работать лучше.
Алгоритм Random Forest
Итак, что вы делаете, чтобы выбрать подходящее место? Ищите информацию в Интернете: вы можете прочитать множество различных отзывов и мнений в блогах о путешествиях, на сайтах, подобных Кью, туристических порталах, — или же просто спросить своих друзей.
Предположим, вы решили узнать у своих знакомых об их опыте путешествий. Вы, вероятно, получите рекомендации от каждого друга и составите из них список возможных локаций. Затем вы попросите своих знакомых проголосовать, то есть выбрать лучший вариант для поездки из составленного вами перечня. Место, набравшее наибольшее количество голосов, станет вашим окончательным выбором для путешествия.
Вышеупомянутый процесс принятия решения состоит из двух частей.
- Первая заключается в опросе друзей об их индивидуальном опыте и получении рекомендации на основе тех мест, которые посетил конкретный друг. В этой части используется алгоритм дерева решений. Каждый участник выбирает только один вариант среди знакомых ему локаций.
- Второй частью является процедура голосования для определения лучшего места, проведенная после сбора всех рекомендаций. Голосование означает выбор наиболее оптимального места из предоставленных на основе опыта ваших друзей. Весь этот процесс (первая и вторая части) от сбора рекомендаций до голосования за наиболее подходящий вариант представляет собой алгоритм случайного леса.
Технически Random forest — это метод (основанный на подходе «разделяй и властвуй»), использующий ансамбль деревьев решений, созданных на случайно разделенном датасете. Набор таких деревьев-классификаторов образует лес. Каждое отдельное дерево решений генерируется с использованием метрик отбора показателей, таких как критерий прироста информации, отношение прироста и индекс Джини для каждого признака.
Любое такое дерево создается на основе независимой случайной выборки. В задаче классификации каждое дерево голосует, и в качестве окончательного результата выбирается самый популярный класс. В случае регрессии конечным результатом считается среднее значение всех выходных данных ансамбля. Метод случайного леса является более простым и эффективным по сравнению с другими алгоритмами нелинейной классификации.
Создание классификатора с использованием Scikit-learn
Вы будете строить модель на основе набора данных о цветках ириса, который является очень известным классификационным датасетом. Он включает длину и ширину чашелистика, длину и ширину лепестка, и тип цветка. Существуют три вида (класса) ирисов: Setosa, Versicolor и Virginica. Вы построите модель, определяющую тип цветка из вышеперечисленных. Этот датасет доступен в библиотеке scikit-learn или вы можете загрузить его из репозитория машинного обучения UCI.
Начнем с импорта datasets из scikit-learn и загрузим набор данных iris с помощью load_iris() .
Как оптимизировать мою модель случайного леса в Scikit Learn (Python)
У меня есть случайная модель леса с использованием Scikit Learn, как показано здесь:
Я пытался оптимизировать свою модель, но пока не добился успеха. Самая высокая точность, которую я достиг в тестовом наборе данных, составляет 78%. Есть ли у вас какие-либо идеи или шаги, которые я мог бы предпринять, чтобы улучшить мою модель?
2. Разделение набора данных на учебные и проверочные данные
Теперь разделим данные с использованием функции Scikit-learn train_test_split . Мы хотим дать модели как можно больше учебных данных. Однако нужно, чтобы в нашем распоряжении было бы достаточно данных для проверки модели. В целом можно сказать, что, по мере роста количества строк в наборе данных, растёт и объём данных, которые можно рассматривать в качестве учебных.
Например, если есть миллионы строк, можно разделить набор, выделив 90% строк на учебные данные и 10% — на проверочные. Но исследуемый набор данных содержит лишь 569 строк. А это — не так уж и много для тренировки и проверки модели. В результате для того, чтобы быть справедливыми по отношению к учебным и проверочным данным, мы разделим набор на две равные части — 50% — учебные данные и 50% — проверочные. Мы устанавливаем stratify=y для обеспечения того, чтобы и в учебном, и в проверочном наборах данных присутствовало бы то же соотношение 0 и 1, что и в исходном наборе данных.
Недостатки алгоритма
- Для реализации алгоритма случайного дерева требуется значительный объем вычислительных ресурсов.
- Большой размер моделей.
- Построение случайного леса отнимает больше времени, чем деревья решений или линейные алгоритмы.
- Алгоритм склонен к переобучению на зашумленных данных.
- Нет формальных выводов, таких как p-values, которые используются для оценки важности переменных.
- В отличие от более простых алгоритмов, результаты случайного леса сложнее интерпретировать.
- Когда в выборке очень много разреженных признаков, таких как тексты или наборы слов (bag of words), алгоритм работает хуже чем линейные методы.
- В отличие от линейной регрессии, Random Forest не обладает возможностью экстраполяции. Это можно считать и плюсом, так как в случае выбросов не будет экстремальных значений.
- Если данные содержат группы признаков с корреляцией, которые имеют схожую значимость для меток, то предпочтение отдается небольшим группам перед большими, что ведет к недообучению.
- Процесс прогнозирования с использованием случайных лесов очень трудоемкий по сравнению с другими алгоритмами.
Преимущества алгоритма
- Имеет высокую точность предсказания, которая сравнима с результатами градиентного бустинга.
- Не требует тщательной настройки параметров, хорошо работает из коробки.
- Практически не чувствителен к выбросам в данных из-за случайного семплирования (random sample).
- Не чувствителен к масштабированию и к другим монотонным преобразованиям значений признаков.
- Редко переобучается. На практике добавление деревьев только улучшает композицию.
- В случае наличия проблемы переобучения, она преодолевается путем усреднения или объединения результатов различных деревьев решений.
- Способен эффективно обрабатывать данные с большим числом признаков и классов.
- Хорошо работает с пропущенными данными – сохраняет хорошую точность даже при их наличии.
- Одинаково хорошо обрабатывает как непрерывные, так и дискретные признаки
- Высокая параллелизуемость и масштабируемость.

Читайте также: