Как сделать семантическое ядро в кей коллекторе
Добавил пользователь Валентин П. Обновлено: 08.10.2024

Существует множество методик работы настройки Кейколлектора и обработки семантики с его помощью. В этом посте я опишу свои методы работы, которые отличаются простотой и по моему опыту дают хорошие результаты.
Статья не для новичков. Поэтому тем, кто впервые сталкивается с программой Кейколлектор, рекомендую предварительно ознакомиться с официальной справкой.
Итак, инструкция по настройке и работе KeyCollektor для обработки инфо-запросов
Подготавливаем софт к работе. Первым делом настраиваем:
- фильтры — для поиска и удаления мусорных запросов;
- видимость колонок — для удобства работы и последующего экспорта;
- саму программу — для комфортной работы и минимизации вероятности блокировки от ПС.
Настройка фильтров
Навигация по тексту
Настраиваем базовые фильтры по фразам

Пример настроек фильтра KeyCollektor по колонке с ключевыми фразами
Почему именно так?
- Убираем однословники, т.к. двигать зайт по ним нецелесообразно, кроме очень редких случаев. К тому же, если мы пилим инфо-сайт, то однословник не даёт нам полной картины по интенту, а это очень важно.
- Убираем фразы, состоящие более чем из 8 слов, т.к. по этим фразам Вордстат Яндекса не даст нам частотку. (Хотя отмечу, что частотность таких длинных фраз собрать можно. На текущий день сервис Rush-Analytics даёт такую возможность. Но это уже тема отдельного поста).
- Убираем фразы с повторами слов — тут всё понятно.
- Убираем фразы со служебными символами. Например, если собираем ядро под RU-сегмент, то этот фильтр уберёт все мусорные фразы с символами i, который характерен для UA-сегмента.
Фильтруем по частотности

Фильтр по точной частотности в Кейколлекторе
Частотность, равная нулю означает, что за последний месяц не было показов рекламы в ПС Яндекс по данному запросу. Нам такие запросы не интересны, т.к. высока вероятность, что их никто и не вводил в поиск. Тут правда стоит учитывать сезонность вашей тематики.
Важный фильтр по KEI — убираем фразы-пустышки
По этому фильтру у меня есть отдельный подробный пост как фильтровать фразы по KEI и почему это эффективно. Почитайте тут.
Сами настройки фильтра выглядят так:

Настройки фильтра по KEI
Значение KEI задаётся формулой в настройках программы на одноимённой вкладке:

Формула KEI
Саму формулу можете скопировать и вставить в программу:
Фильтр убирает фразы-пустышки. Данная формула KEI представляет собой отношение базовой частотности к точной. Чем больше это отношение, тем больше вероятность того, что фраза пустая с точки зрения целесообразности оптимизации под неё. Такие слова хоть и имеют большую частоту, но по факту запрашиваются в поиске крайне мало. Это нам не интересно, фильтруем.
Почему я ставлю больше или равно 95 в фильтре? Такую степень фильтрации вывел опытным путём, неплохо работает при чистке фраз.
Настраиваем видимость колонок
Как показала практика, наиболее нужные колонки в программе:
- Фраза;
- Базовая частотность [WS];
- Частотность в кавычках “ ” [WS];
- Точная частотность “!” [WS];
- Значение KEI.
Для удобства настраиваем шаблон вида в самом Кейколлекторе:

И аналогично указываем нужные колонки в файле экспорта:

Настраиваем программу KeyCollektor
Удобство пользования зависит от правильно расположенных на панели кнопок быстрого доступа. Тут всё индивидуально. Я например, перенёс в быстрый доступ кнопки поиска неявных дублей и анализ групп:

Можно вообще вынести наиболее полезные кнопки на панель, остальное скрыть, освободив больше рабочего пространства. Например, так:

Тут всё индивидуально. Кнопки на панель быстрого доступа отправляются из контекстного меню по клику правой кнопки мыши.
Далее настраиваем вкладки.
Yandex Wordstat

Настройки вкладки Yandex Wordstat
Google Adwords

Настройки вкладки Google Adwords
На вкладке надо также указать аккаунт Google Adwords для сбора статистики. Не используйте свой основной аккаунт. Его могут заблокировать.
Yandex Direct
Настройка вкладки Yandex Direct — Часть №1 Настройка вкладки Yandex Direct — Часть №2
На вкладке надо указать аккаунты Яндекс Директ. Желательно штук 10. Также как и с Adwords не используйте свой основной аккаунт в Яндексе. Его могут заблокировать.
Сеть

Настройка вкладки Сеть
Прокси можно бесплатно взять в сервисе Hideme. Важно при этом прокси использовать только для снятия частотности и менять каждый день. Также перед стартом парсинга проверяйте прокси в Яндексе.
Вкладка Антикапча

Настройка вкладки Антикапча
Если у вас валится много капчи, то совет такой: сделайте принудительную очистку данных об авторизации и удалите куки коллектора.
Данные об авторизации чистятся на вкладке настроек Yandex Direct — там такая большая кнопка есть:

Куки удаляются в папке Preferences, которая лежит где установлен Кей Коллектор:

Куки Кей Коллектора
У вас этот путь может быть другим.
Вкладка KEI
YandexWordstatBaseFreq / ( YandexWordstatQuotePointFreq + 1.0001 )
Анализ неявных дублей

Бонус: где брать ключи для обработки.
Понятно, что прежде чем обрабатывать ключи, их надо где-то собрать. Для прямого парсинга Вордстат как ни странно, не очень эффективен из-за ограничений по глубине парсинга. Поэтому я делаю так: собираю начальные ключи по данным сервиса Кейсо. Также можно брать массивы по запросам-маскам из баз Букварикса или МОАВа. Далее загружаем выборки в Кейколлектор, собираем явные минус фразы (инструмент анализа групп вам в помощь) и дальше парсим список через вордстат и подсказки.
Итак, сам алгоритм
В итоге получается достаточно хорошая и полная семантика, имеющая спрос в ПС. Останется правильно кластеризовать, составить ТЗ, опубликовать материалы и ждать профита)

Key Collector — один из основных инструментов SEO-оптимизатора. Эта программа, созданная для подбора семантического ядра, входит в категорию маст-хэв инструментов для продвижения. Она так же важна, как скальпель для хирурга или штурвал — для пилота. Ведь SEO-оптимизация без ключевых слов немыслима.
В этой статье рассмотрим, что такое Кей Коллектор и как с ним работать.
Для чего нужен Key Collector
Подобрать ключевые слова для сайта можно разными способами. Если проект создан сугубо под Рунет и не ориентирован на множество ключевых слов (например, сайт-визитка), можно воспользоваться сервисом Яндекс.Wordstat. Для облегчения работы с Вордстатом можно применить программу Словоёб, которая является бесплатным и урезанным по функционалу вариантом Кей Коллектора. Но когда нужна профессиональная работа с семантическим ядром и брать запросы нужно из разных источников, а не только из Вордстата, понадобится помощь инструмента KeyCollector.
Где взять?
Программа платная, но её цена абсолютно адекватна — 1800 рублей. Это один из немногих SEO-инструментов, наряду с FastTrust, который по карману большинству оптимизаторов и владельцев сайтов со старта. Другие крайне нужные сервисы, например, Ahrefs, стоят 100 долларов в месяц, а то и больше.
Купить Key Collector можно на его официальном сайте. Там вы найдёте подробную инструкцию по оплате, лицензии, скачиванию, установке и активации программы.
Как настроить Key Collector
В первую очередь потребуются специально созданные аккаунты для работы с Яндекс.Вордстатом (аккаунты Яндекса). Не рекомендуется использовать настоящий аккаунт, так как его могут забанить. Лучше создать штук 5 специальных аккаунтов именно для работы с программой. О том, как это сделать, я рассказал в статье «Как создать почту в Яндекс«.
Затем зайдите в настройки (кнопка шестерёнки в панели в верхнем левом углу окна программы) и найдите вкладку «Yandex.Direct«.
После всех операций получится примерно следующее:

Также можно получать данные из Google AdWords. Для этого также нужно создать отдельный аккаунт. Если с этим моментом возникают сложности, прочитайте статью о том, как создать почту Gmail (аккаунт Google).
Но и это ещё не всё. Теперь нужно создать аккаунт Google AdWords, который будет привязан к данному аккаунту Google. Без аккаунта в AdWords получать данные по ключевым словам будет невозможно, так как они берутся именно оттуда. При создании аккаунта выберите язык, часовой пояс и валюту. Учтите, что эти данные нельзя будет изменить.
После создания аккаунта AdWords вновь откройте настройки Key Collector и вкладку «Google.AdWords«. Здесь в настройках рекомендуется использовать только один аккаунт Google.

Антикапча
Распознавание капчи — это платная услуга, но 10 долларов хватает минимум на месяц. К тому же если вы не занимаетесь парсингом поисковиков ежедневно, этой суммы хватит и на год.

Прокси
По умолчанию программа использует для парсинга ваш основной IP-адрес. Если пользоваться Кей Коллектором часто вам не потребуется, на настройки прокси можно забить. Но если вы часто работаете с программой, поисковики могут часто подсовывать вам капчу и даже временно банить ваш IP. К тому же будут страдать все пользователи, которые выходят в Сеть под общим IP. Такая проблема встречается, например, в офисах.
Также трудности при парсинге Яндекса с основного IP могут испытывать пользователи из Украины.
Найти бесплатные прокси, которые всё ещё не в бане поисковиков, бывает довольно сложно. Если у вас есть список таких адресов, введите их в настройках во вкладке «Сеть«. Затем нажмите на кнопку «Добавить строку«.

Другой вариант — создайте файл с адресами в формате IP:порт, скопируйте их в буфер обмена и добавьте в коллектор с помощью кнопки «Добавить из буфера«.
Но я рекомендую подключить платный VPN от hidemy.name. В этом случае на компьютер устанавливается приложение, которое включает/выключает VPN по требованию. В этом приложении также можно изменять сам прокси и его страну. Дополнительно не придётся ничего настраивать. Просто включаете VPN и комфортно работаете с Коллектором.
Я перечислил основные настройки, которые нужны для старта работы. Советую самостоятельно пройтись по всем вкладкам и изучить настройки программы. Может быть, вы найдёте пункты в настройках, которые окажутся нужны именно вам.
Подбор ключевых слов с Key Collector

В Коллекторе удобно сортировать ключевые слова по группам. Мне удобно, когда иерархия групп в проекте соответствует будущей структуре сайта, поэтому первая группа (группа по умолчанию) у меня соответствует главной странице сайта.

Сначала нужно задать регион:


Теперь нужно нажать на кнопку «Начать сбор«.
Всё, можно пойти заварить кофе или переключиться на другие задачи. Кей Коллектору потребуется некоторое время, чтобы спарсить ключевые фразы.
В результате отобразится примерно следующее:

Стоп-слова

Затем нужно нажать на плюсик:

И ввести основные стоп-слова.
Вероятно, вы заметили, что в программе есть большое количество различных опций при работе с ключевыми словами. Я объясняю основные, самые простые операции в Key Collector.
Рекомендую самостоятельно изучить программу и внимательно прочитать официальный мануал.
Работа с частотностью запросов
После фильтрации по минус-словам можно запустить парсинг по частотности.
В Коллекторе это делается следующим образом:

Второй способ собрать частотность (более медленный):

Если вы точно знаете, что частотность ниже определённого значения вас не интересует, можно задать порог в настройках программы. В этом случае фразы с частотностью ниже порога вообще не будут попадать в список. Но так можно упустить перспективные фразы, поэтому я эту настройку не использую и вам не советую. Впрочем, действуйте по своему усмотрению.
В итоге получается более-менее пригодное для последующей работы семантическое ядро:

Обратите внимание, что это семантическое ядро — лишь пример, созданный только для демонстрации работы программы. Оно не годится под реальный проект, так как слабо проработано.
Правая колонка Yandex.Wordstat

Google и Key Collector
Запросы из статистики Google парсятся по аналогии с Яндексом. Если вы создали аккаунт Google и аккаунт AdWords (как мы помним, одного лишь аккаунта Google недостаточно), нажмите на соответствующую кнопку:

В открывшемся окне введите интересующие запросы и запустите подбор. Всё по аналогии с парсингом Вордстата. Если необходимо, в этом же окне укажите дополнительные настройки конкретно для Google (при клике на значок вопроса появится справка).
В итоге вы получите следующие данные по AdWords:

И сможете продолжить работу с семантикой.
Выводы
Мы разобрали базовые настройки Key Collector (то, без чего невозможно начать работать). Также мы рассмотрели самые простые (и основные) примеры использования программы. И подобрали простенькое семантическое ядро, используя статистику Яндекс.Вордстат и Google AdWords.
Как вы понимаете, в статье показано примерно 20% от всех возможностей программы. Чтобы освоить Key Collector, нужно потратить несколько часов и изучить официальный мануал. Но оно того стоит.
Если после этой статьи вы решили, что проще заказать семантическое ядро у специалистов, чем разбираться самому, напишите мне через страницу Контакты, и мы обсудим детали.
И бонусное видео: чувак по имени Derek Brown виртуозно играет на саксофоне. Я даже побывал на его концерте во время джаз-фестиваля, это реально круто.
Вот и настал тот долгожданный день, когда мы наконец-то выпускаем самый развёрнутый в Рунете обзор мощнейшего инструмента по продвижению – программы Key Collector. В рамках данного обзора мы рассмотрим такие важные вопросы, как:
и многое другое.
НО… Имейте в виду, что спустя некоторое время с момента выхода, данный обзор может частично утратить свою актуальность. И сейчас мы объясним почему.
Почему не стоит скачивать ломаные версии Key Collector
Ну и из этого видео Вы уже и сами поняли, что пиратский Key Collector даже пытаться искать не стоит.
Кстати, после того как было записано приведённое выше видео, была найдена еще одна довольно забавная страничка, на которой тоже пытались продать хакнутый Кей Коллектор.
Т.е. Вам предлагают заплатить 650р за версию многолетней давности. Ну Вы уже и так догадались, покупка конкретно этой пиратской копии – это чистой воды тупик, поскольку в случае утраты актуальности (а этот случай неминуем) Вам придется заплатить еще столько же. А потом, когда этот случай произойдёт еще раз, заплатить еще столько же. 3 таких покупки превысят стоимость лицензии.
Итак, плюсов у пиратских копий мы не выявили, чего нельзя сказать о минусах:
- не факт, что Вы вообще добудете пиратскую копию, а если и добудете, то:
- нет доступа к обновлениям (критично);
- рабочим останется далеко не весь функционал (критично);
- даже пиратские копии могут быть платными (ЧТО?!).
Резюмируем: добываете пиратскую копию, обламываетесь (простите за грубость), и идёте покупать лицензию.
Да, мы не спорим, на просторах Рунета можно встретить и относительно свежие версии КейКоллектора, НО:
- они НЕ пиратские, т.е. их просто скачали прямиком у издателя и выложили у себя на сайте, чтобы привлечь трафик (а иногда публикуются прямые ссылки на скачивание с первоисточника, даже без редиректов);
- лицензия к ним приобретается отдельно;
- имеет смысл скачивать программу именно у первоисточника, т.к. самая свежая версия всегда появляется именно там (не критично, т.к. после покупки лицензии Вы запросто сможете обновиться до последней версии).
Итак, с отсутствием плюсов и рядом минусов пиратских копий мы разобрались. Как Вы уже догадались, покупка лицензии (кстати, ее стоимость 1800 рублей) избавит Вас от всех перечисленных выше минусов, кроме одного: с недавнего времени разработчики прекратили поддержку Windows XP (т.к. она уже 15 лет, как морально устарела и не соответствует многим современным требованиям по функционалу и безопасности). Решается этот минус очень просто – переустановкой операционной системы в пользу хотя бы Windows Vista – она тоже морально устарела, но пока еще поддерживается.
Особенности лицензионной копии
Во-первых, цена. 1800р придется заплатить только за первую лицензию. Все последующие обойдутся дешевле – 1100-1400р в зависимости от количества приобретаемых и уже приобретенных лицензий. Однако, даже 1800р – это не много: большинство из Вас за 1 поход в продуктовый магазин закупаются на большую сумму.
Во-вторых, каждая лицензия довольно жестко привязывается к железу компьютера. Т.е. просто так продублировать копию на второй ПК не получится. Более того, даже внести изменения в конфигурацию уже имеющегося ПК тоже просто так не получится. Да, мы не спорим, в случае переустановки операционной системы (причем вне зависимости от версии) действие лицензии сохраняется. Да, мы не спорим, замена жесткого диска тоже не доставит проблем. Но стоит Вам заменить процессор, материнскую плату, оперативную память (даже если Вы добавляете вторую планку в пару к уже имеющейся), видеокарту либо какое-то иное оборудование – лицензия слетает. Да, ее можно восстановить, но об этом чуть позже.
В-третьих, лицензия выдается пожизненно, т.е. ее не придется покупать повторно.
В-четвертых, Вы в любой момент сможете обновиться до самой актуальной версии. Напомним – обновления могут выходить и 2 раза в сутки.
Что такое HID, где и как его узнать, как получить лицензию и как ее заменить
HID – это идентификатор Вашего компьютерного оборудования. Т.е. если взять 2 компьютера, собранных из одних и тех же запчастей, то HID у них будет отличаться. HID Вам понадобится для проведения двух операций:
Как видите, ничего суперсложного в процедуре получения и смены HID нету. Однако, есть пара моментов, о которых мы забыли упомянуть в видео:
3) Получать новый файл лицензии можно не чаще 2 раз в месяц.
Как собрать семантическое ядро с помощью Key Collector’а
Приведённое ниже видео можно условно разделить на 3 части – подготовка рабочих аккаунтов, настройка антикапчи, и непосредственно парсинг (сбор) ключей.
В данном видео мы рассмотрели только бесплатные сервисы, при помощи которых можно собрать достаточно большое количество хороших ключей. Парсинг с платных сервисов рассматривать не стали, поскольку тарифы платных сервисов достаточно сильно кусаются. Например, в бесплатном режиме из сервиса SerpStat спарсить ничего не получится – сервис вернёт ошибку 403, свидетельствующую о том, что использование API в бесплатном режиме заблокировано.

И это несмотря на то, что токен указан правильно. Самый дешевый тариф при этом составляет примерно 1200р/мес (в зависимости от курса доллара). И если платить за Кей Коллектор нужно всего 1 раз, то выкладывать по 1200р/мес не каждый согласится.
Как быстро почистить собранное ядро от мусора; кластеризация поисковых запросов
В этом видео мы расскажем о том, как быстро почистить собранное ядро от лишних поисковых запросов тремя разными способами – с помощью стоп-списка городов, с помощью удаления ключей, фактически являющимися дублями, и с помощью штатного инструмента кластеризации поисковых запросов.
Итак, еще раз: инструмент группировки поисковых запросов в Key Collector хорош по большей части именно ДЛЯ ЧИСТКИ собранных запросов от мусора. Для чистовой кластеризации он мало подходит как минимум потому, что группирует не все запросы.
Также стоит отметить, что эти 3 способа НЕ являются единственными. Есть и другие.
Способ 4 – быстрый фильтр
Просто вводите какое-либо слово и получаете список ключей, в которых содержится это слово. Выглядит это примерно вот так:
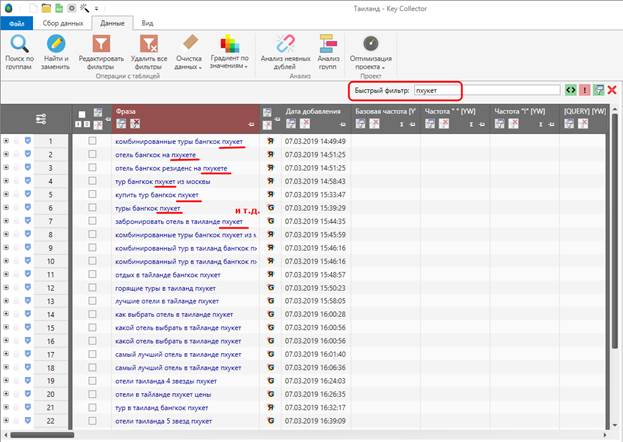
Далее отмечаем ключи галочками, если они лишние, и удаляем.
С одной стороны, способ вполне имеет право на существование. С другой – он, по сути, является полным аналогом очистки с помощью списков стоп-слов. С третьей стороны – данный способ не обязательно использовать именно для чистки ядра от мусора.
Способ 5 – фильтр
Способ аналогичен предыдущему, но более медленный и более функциональный, т.к. позволяет настраивать сложные условия. Выглядит это примерно вот так:
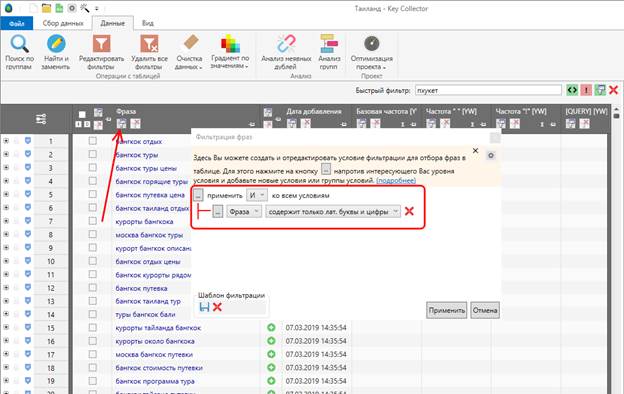
Можно настроить фильтр таким образом, чтобы выводились только ключи, в которых есть латинские буквы и цифры, либо повторяющиеся слова, либо ключи, длина которых не превышает (или наоборот – превышает) сколько-то там слов, и т.д., опций для настройки очень много.
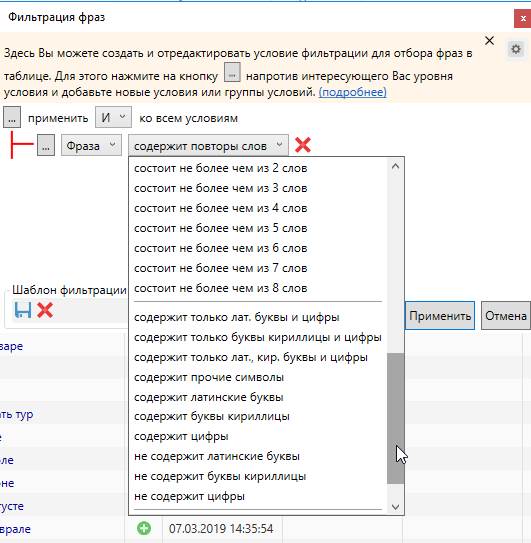
В списке ключей вполне могут попадаться запросы с упоминанием прошлого года. Их следует изучать отдельно, т.к. то, что запрашивали в прошлом году, вполне могут запрашивать и в этом. Поэтому иногда разумнее не удалять ключ из списка, а скорректировать его.
Способ 6 – ручная очистка
Это самый долгий способ, поскольку приходится вручную просматривать весь список в поисках мусора. Если список ключей насчитывает десятки тысяч поисковых запросов – дело может затянуться на несколько дней, плюс к этому, Вы гарантированно что-нибудь упустите. Поэтому сейчас мы покажем пару лайфхаков, которые позволят немного ускорить этот процесс.
Лайфхак 1 - если при просмотре Вы нашли ключ, который явно Вам не подходит, можно разбить ключ на слова и частично их внести в список стоп-слов.
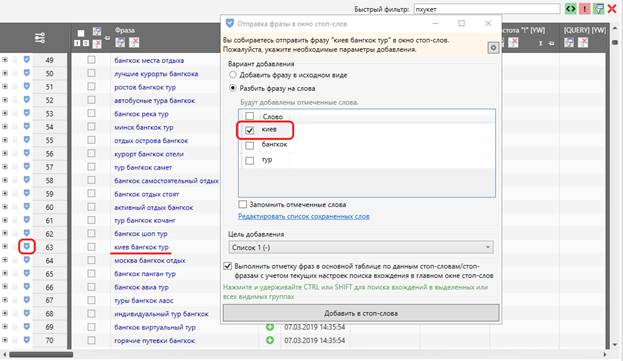
После добавления Киева в список стоп-слов, в таблице автоматически пометятся все ключи, содержащие в себе Киев.
Лайфхак 2 – настраиваем фильтр таким образом, чтобы в таблице были показаны только неотмеченные запросы, т.е. вот таким образом:
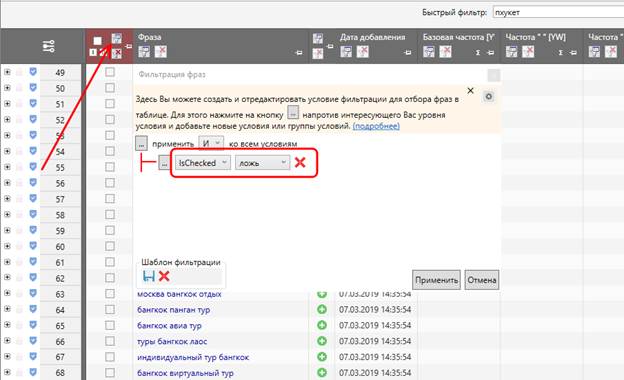
Это необходимо для того, чтобы скрыть те ключи, которые галочкой уже отмечены – чтоб не мешали.
С первичной чисткой, будем считать, разобрались. Теперь можно переходить к сбору данных, которые подскажут, какие еще ключи имеет смысл убрать из списка.
Сбор частот поисковых запросов двумя способами
Анализ поисковых запросов на сезонность (точнее – сезонозависимость)
Что такое сезонозависимый поисковый запрос? Очень просто – это запрос, популярность которого сильно меняется от сезона к сезону.
Анализ поисковых запросов необходимо проводить как минимум с двумя целями:
- выявление накрученных поисковых запросов;
- выявление сезонозависимых поисковых запросов в отдельную группу для их дальнейшего углубленного анализа, чтобы понять, какие именно запросы Вы успеете продвинуть к старту сезона, а какие – нет, и в какой последовательности вообще следует продвигать ключи.
С теми же пластиковыми окнами. Почему зимой на них падает спрос? Правильно – потому что зимой холодно, а удаление уже имеющегося окна (а без него никак) гарантированно приведет к охлаждению всей квартиры до уличной температуры. Летом, когда у всех окна нараспашку, такой проблемы нет. Отсюда простейший вывод – подготовительные работы нужно начинать именно зимой, потому что весной уже начнётся рост спроса, а Вы к этому уже должны быть готовы, т.к. летом будет самая жара как в плане температуры на улице, так и в плане продаж.
Мониторинг позиций с помощью Key Collector’а и СловоЁБа
В целом процедура сбора позиций сайта с помощью СловоЁБа выглядит также, разумеется, если не учитывать различия в интерфейсе.
И еще одно – если Вы не хотите покупать прокси и не хотите подставлять под удар свой основной IP – можете воспользоваться VPN-сервисами. Например, Betternet. Сервис позиционируется как платный, но с демодоступом. По факту же платить за него не обязательно. Тем не менее, сервис реально качественный и обеспечивает достаточно высокую скорость передачи данных, а потому не грех поддержать ребят рублём на добровольной основе.
Причин медленной работы может быть несколько. Начнём с технических причин.
Слабый процессор. Особенно это касается ультрабюджетных ноутбуков, базирующихся на Intel’овских Celeron’ах и Atom’ах, а также на AMD-процессорах E1 и E2 серий. Программно тут уже ничего не сделаешь. Сюда же можно отнести и медленное интернет-соединение.
Нехватка оперативной памяти. Возможно, но крайне маловероятно, т.к. ОЗУ он потребляет очень скромно:
Так что даже с 2 Гб ОЗУ и Windows 10 на борту памяти должно хватать.
Установлена не та версия операционной системы. Кто не в курсе, та же Windows 10 имеет 2 версии – 32-разрядную (x86) и 64-разрядную (x64). Если у Вас 64-разрядная система, но при этом установлена x86-версия Кей Коллектора – выделите 2 минуты и поменяйте версию Коллектора на x64. В худшем случае это ничего не даст, в лучшем – повысит производительность программы.
Ну а теперь самое интересное – повышение производительности с помощью прокси-серверов. Без преувеличения, производительность вырастает в несколько раз, т.к. одновременно обрабатывается в несколько раз больше запросов, а это жирный плюс, если Вы работаете с очень крупным семантическим ядром.

Сбор семантики в Яндекс.Wordstat — это по большей части ручная работа с использованием программных помощников. В первую очередь из их числа мы используем Яндекс Wordstat Assistant — это расширение для браузеров, которое позволяет значительно ускорить ручной сбор слов с помощью сервиса подбора слов Яндекс.
Как собрать семантику в Wordstat:
Справа вы увидите колонку запросов, похожих на основной. Их тоже нужно смотреть, так как среди них могут быть подходящие.
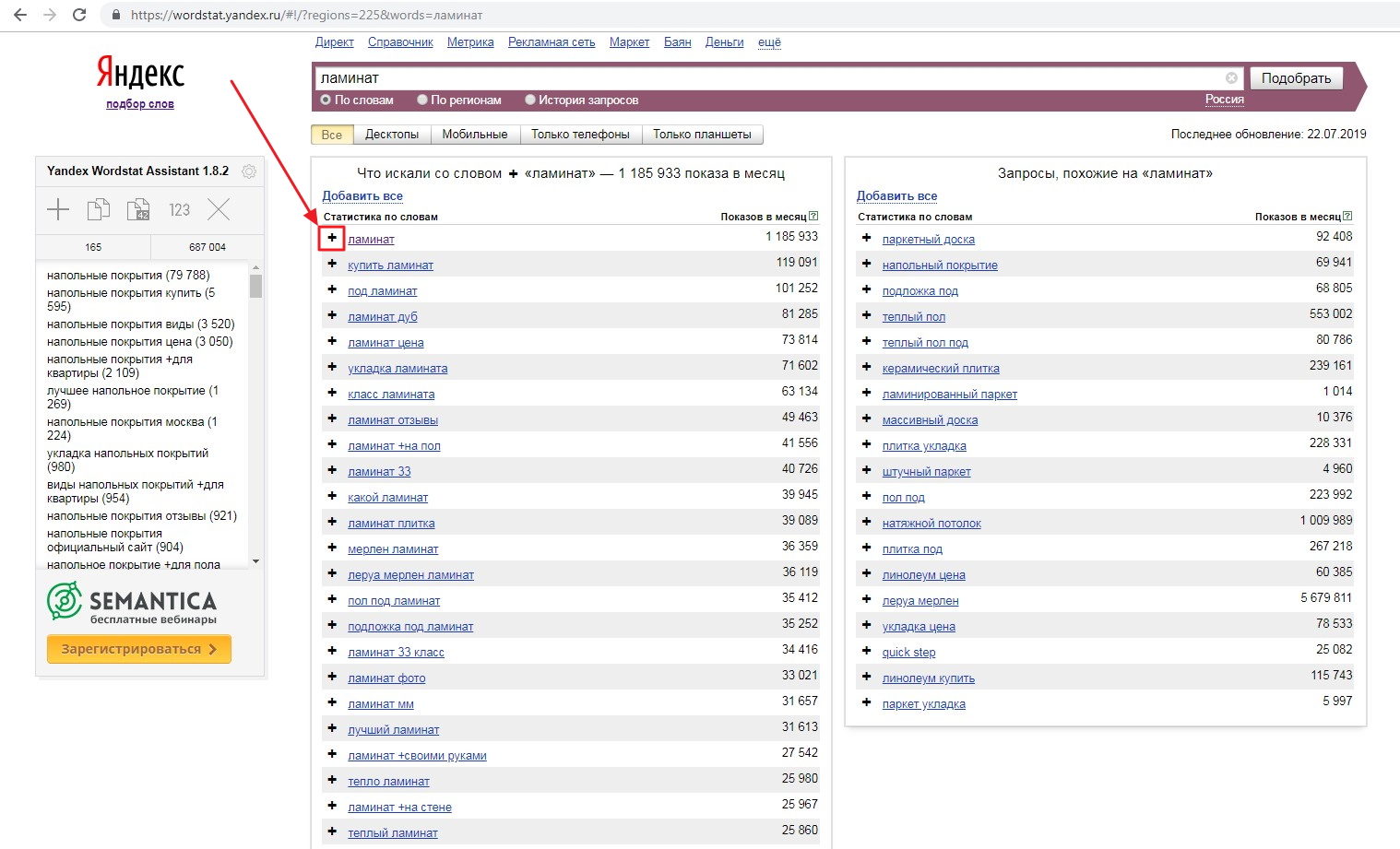
Возможность добавить в список фразы вручную полезна, когда уже есть сохраненный список, который нужно обновить или дополнить. Уже добавленные слова в общем списке обесцвечиваются, чтобы вы не добавляли их дважды.
- Вставить список ключевых слов из Wordstat в редактор таблиц (например, Microsoft Office Excel или OpenOffice Calc). Список сохраняется при закрытии браузера, а также синхронизируется между открытыми вкладками.
- После сбора семантики нужно вручную разбить запросы на кластеры и подобрать оптимальные страницы для будущего продвижения. Также можно использовать автоматические сервисы кластеризации — например, Coolakov. Конечно, это должно происходить параллельно с анализом поисковой выдачи. Чтобы выйти в топ поиска, важно понимать, какой топ поисковики сформировали на сегодняшний день, к какому типу относятся те или иные ключевики – к коммерческому или информационному классу. Далее оптимизатор формирует карту запросов и составляет техническое задание для копирайтеров.
Чем хорош и чем плох Яндекс.Wordstat?
Сбор семантики с помощью Key Collector

- Чтобы правильно собрать семантику для сайта, нужно указывать регион продвижения, по которому будет собираться статистика.
Важно!

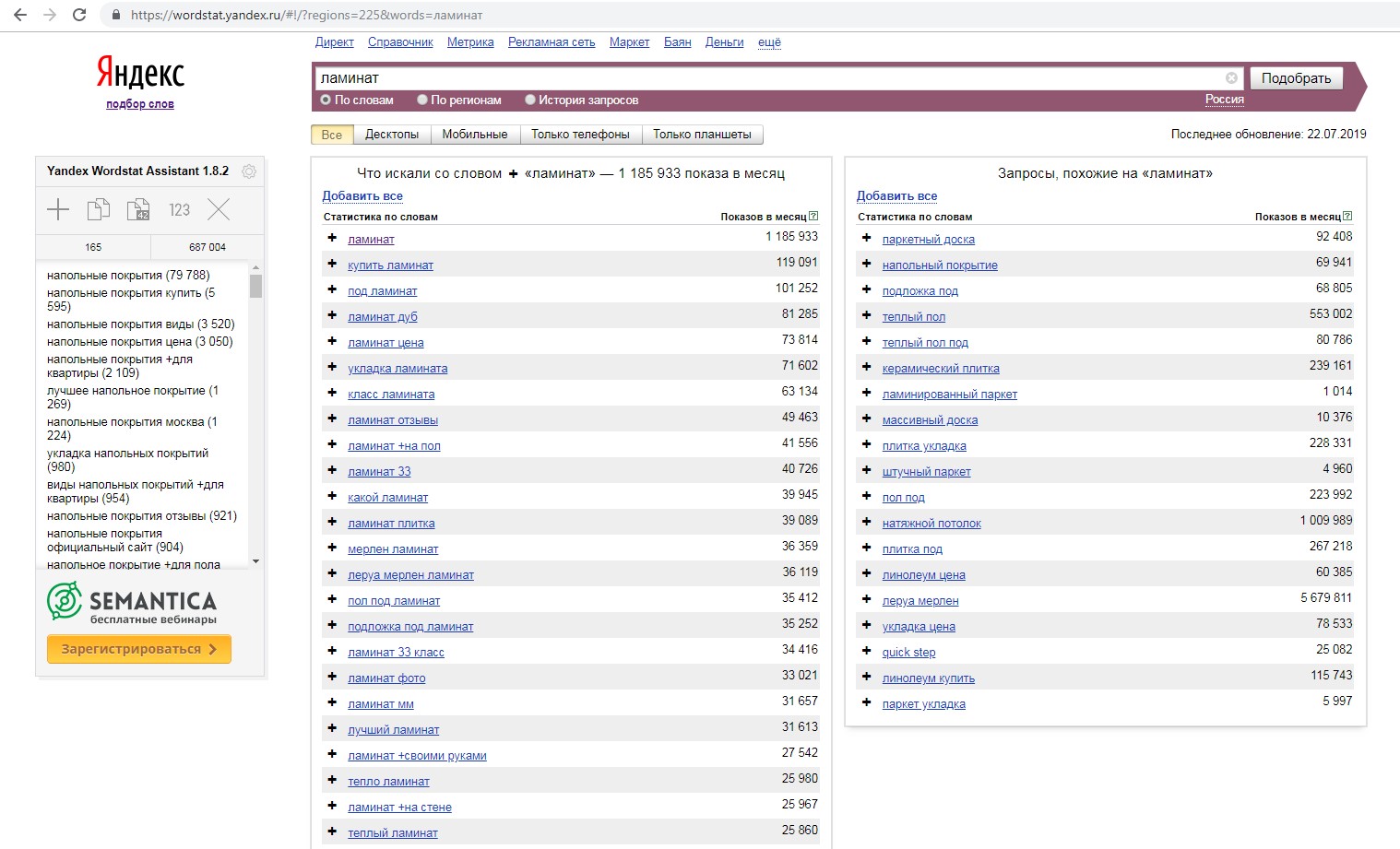
Сначала необходимо определить все группы запросов и их синонимы. С этим отлично справляется вышеупомянутый сервис Яндекс.Wordstat:
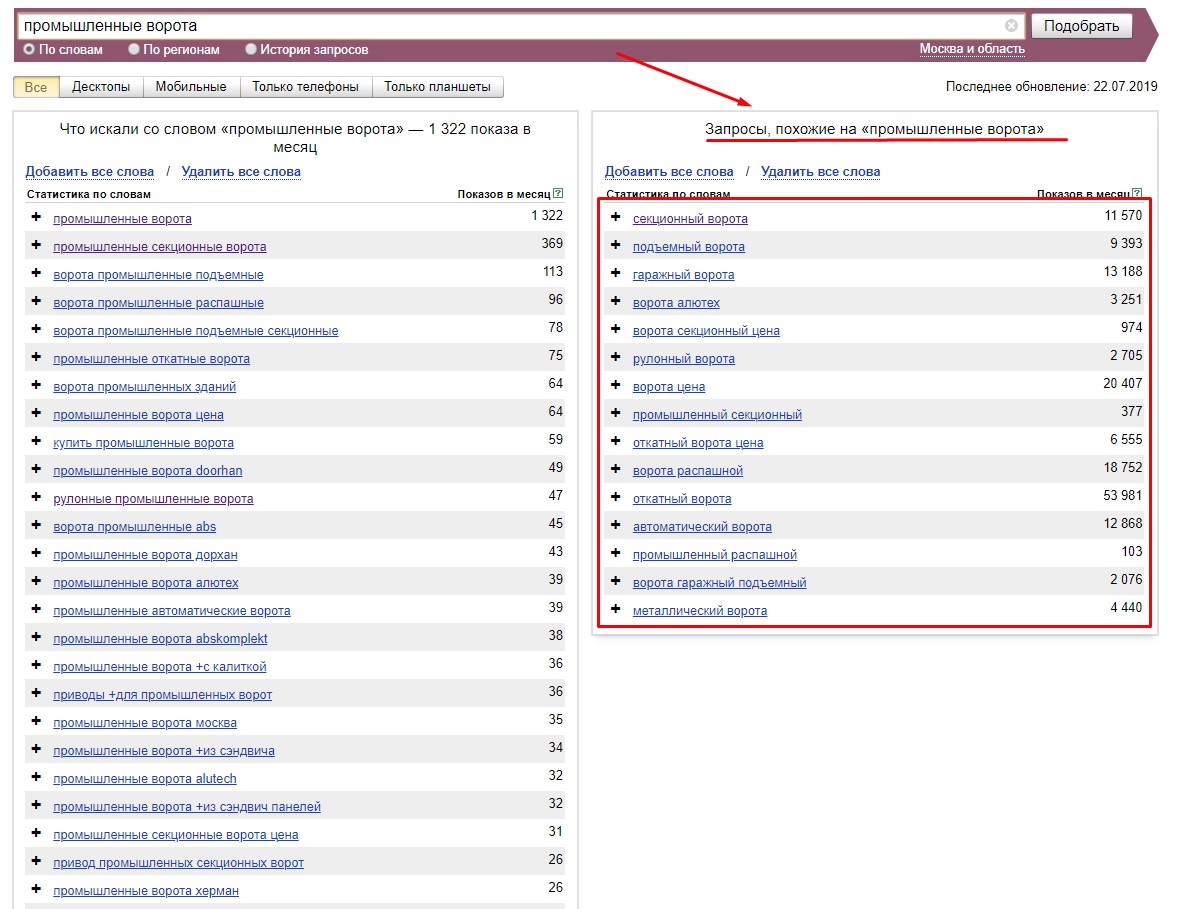
Левый столбец показывает все вариации запроса и разные словоформы, правый столбец — запросы, похожие на искомый.
После того, как были собраны все основные группы, загружаем ключевые запросы в 4 вкладки на консоли Key Collector:
Что это за вкладки:
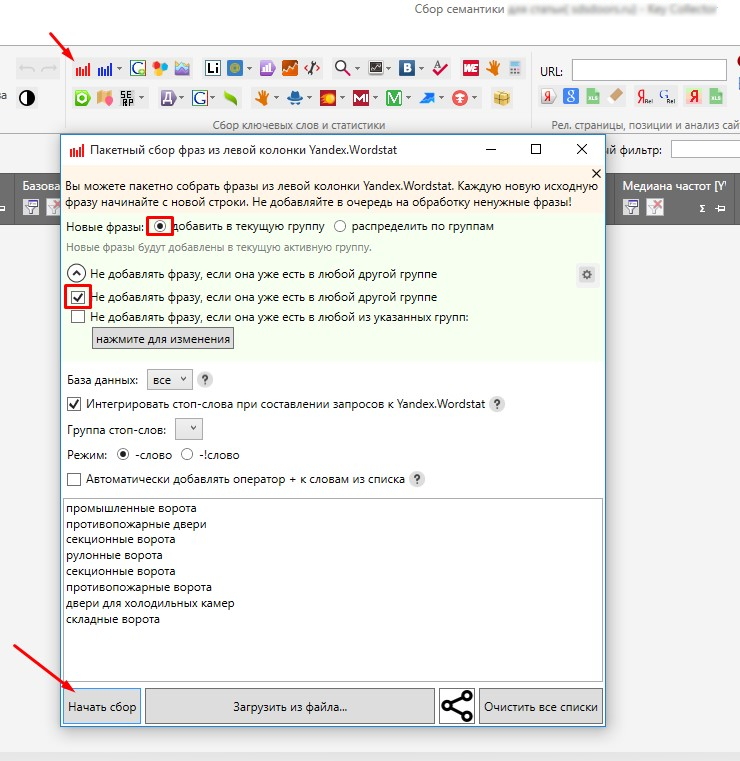
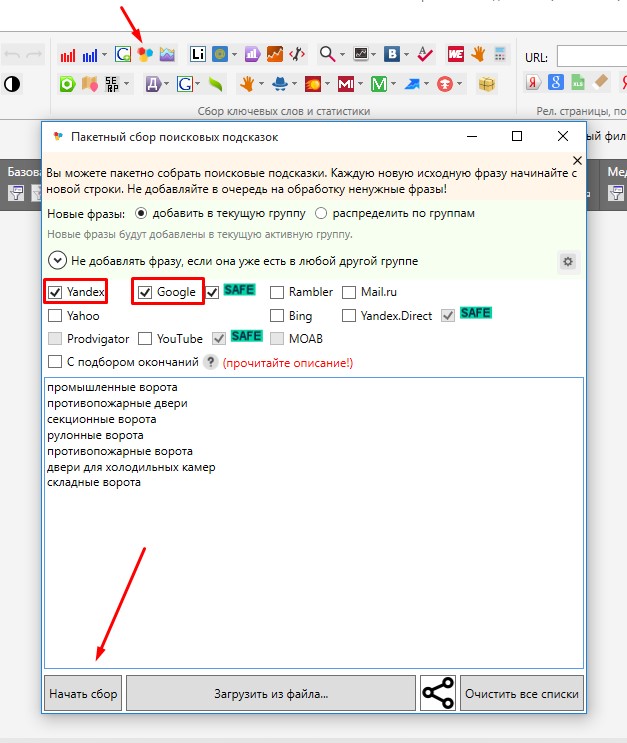
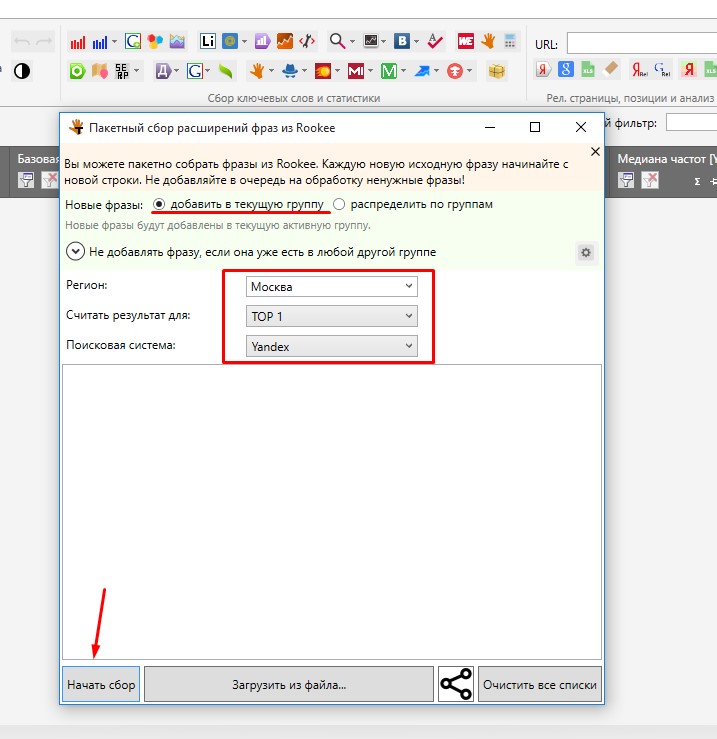
Загружаем фразы и указываем регион продвижения и поисковую систему, откуда необходимо собрать запросы.
После парсинга нужно определить частотность поисковых запросов с помощью сбора статистики Yandex.Direct:
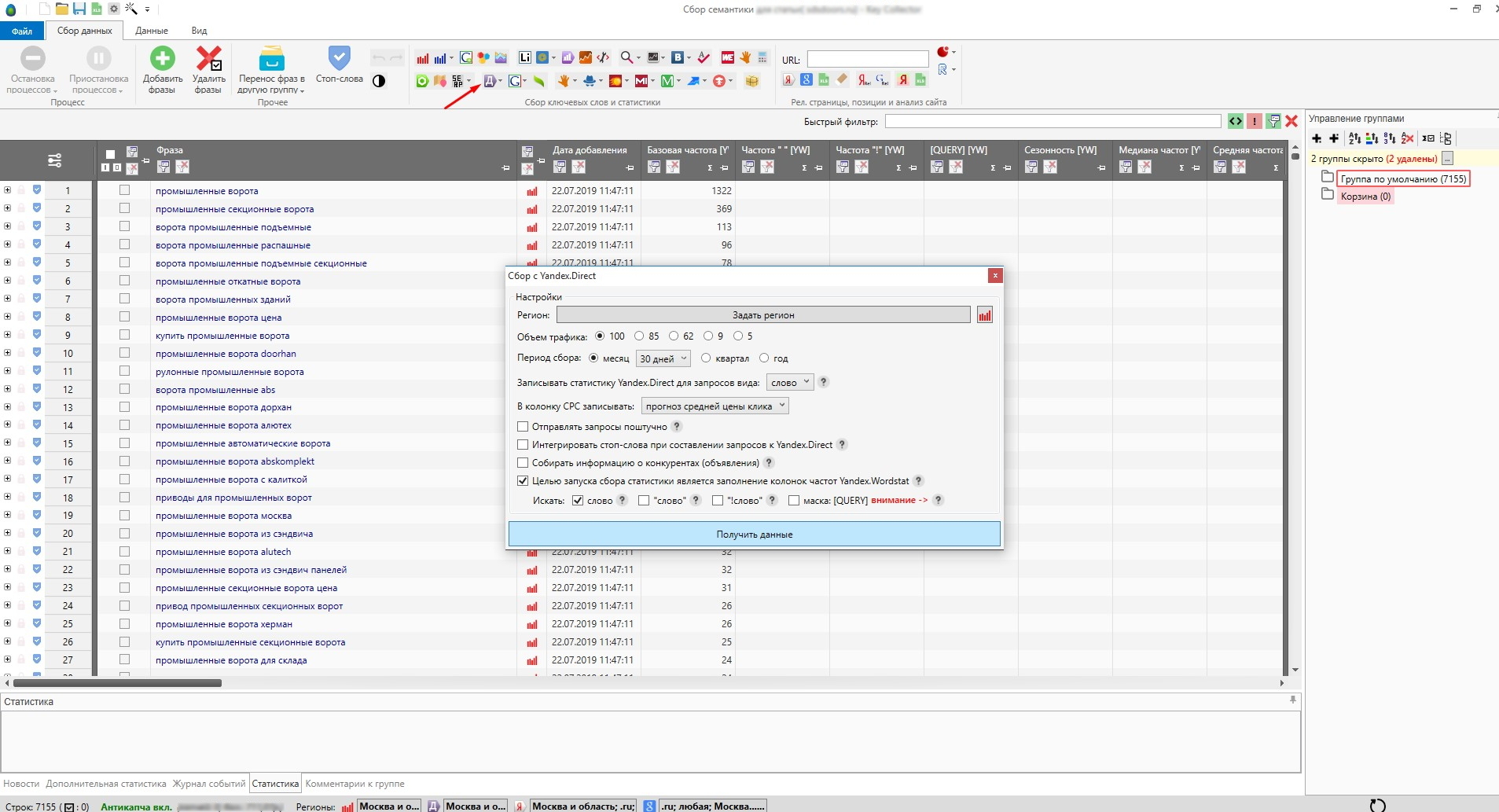
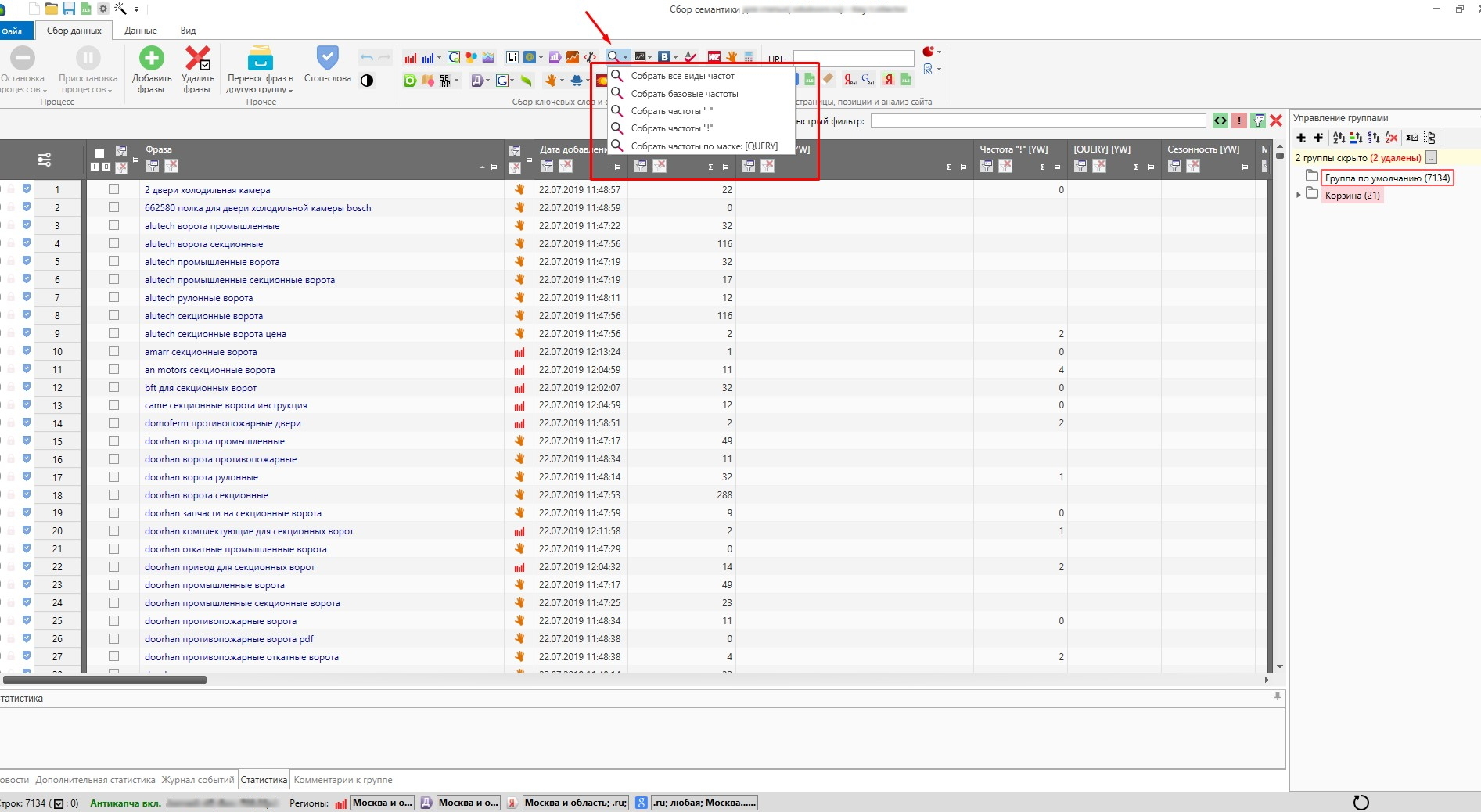
Каким образом это можно сделать:
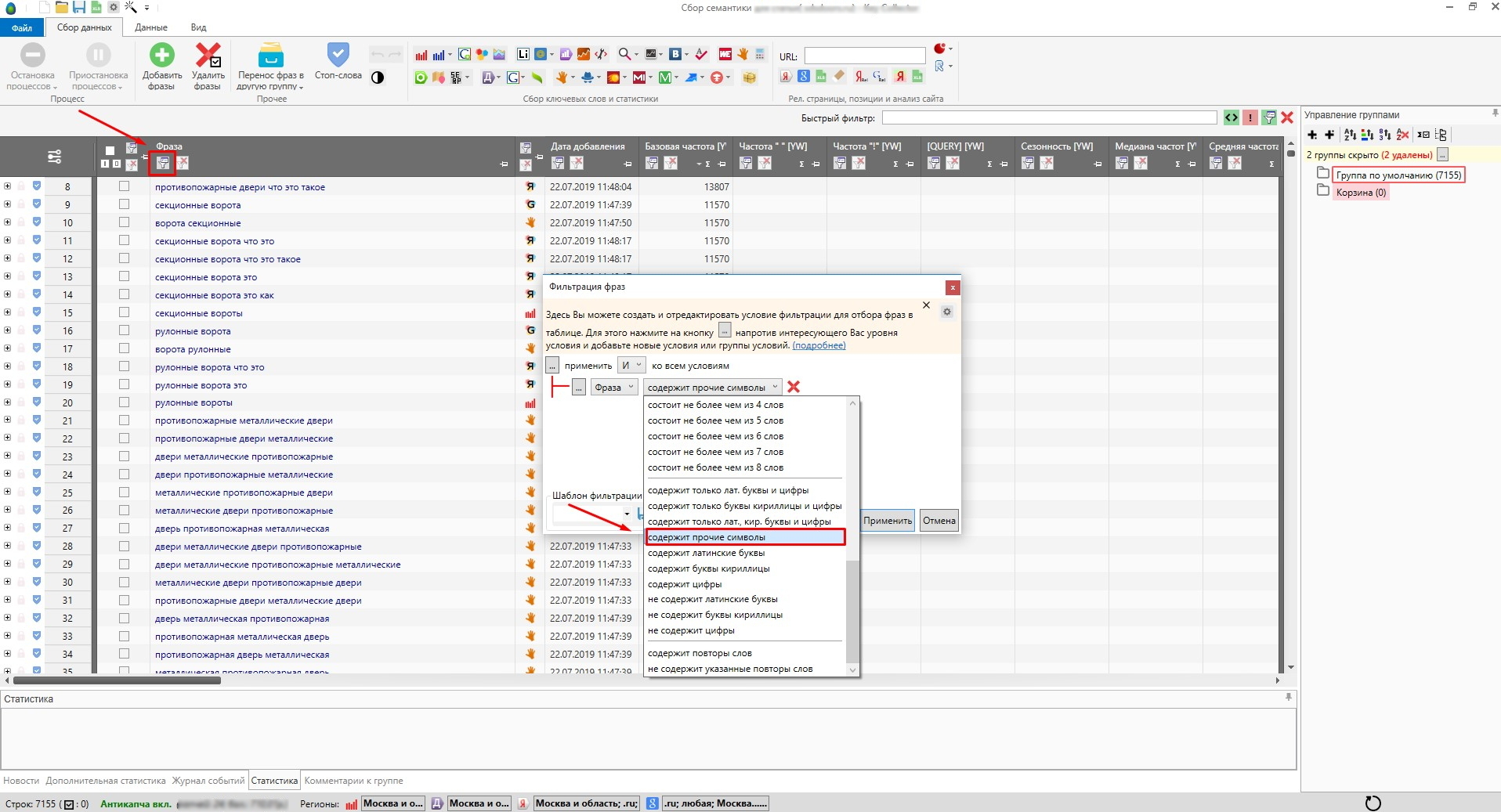
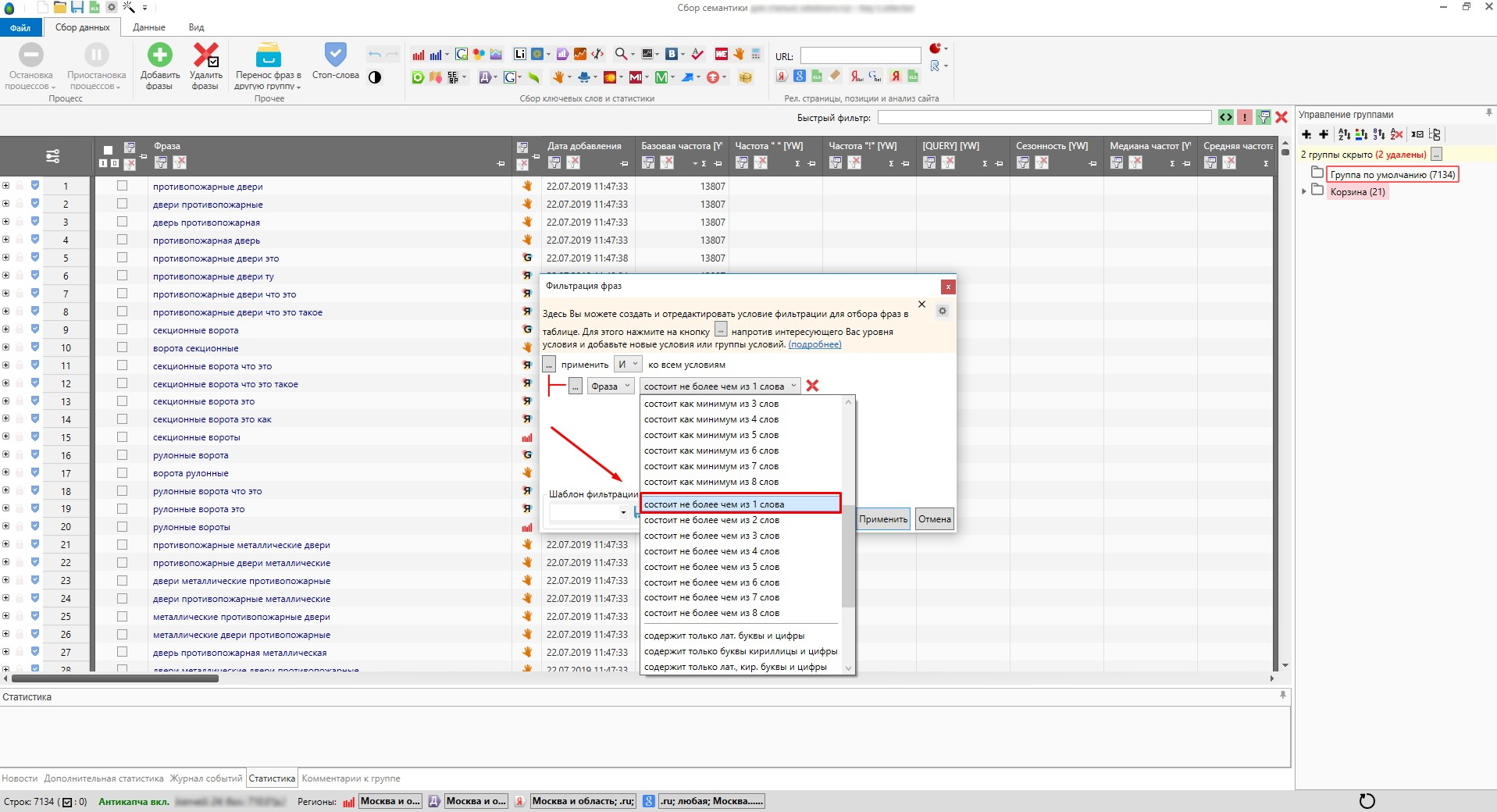
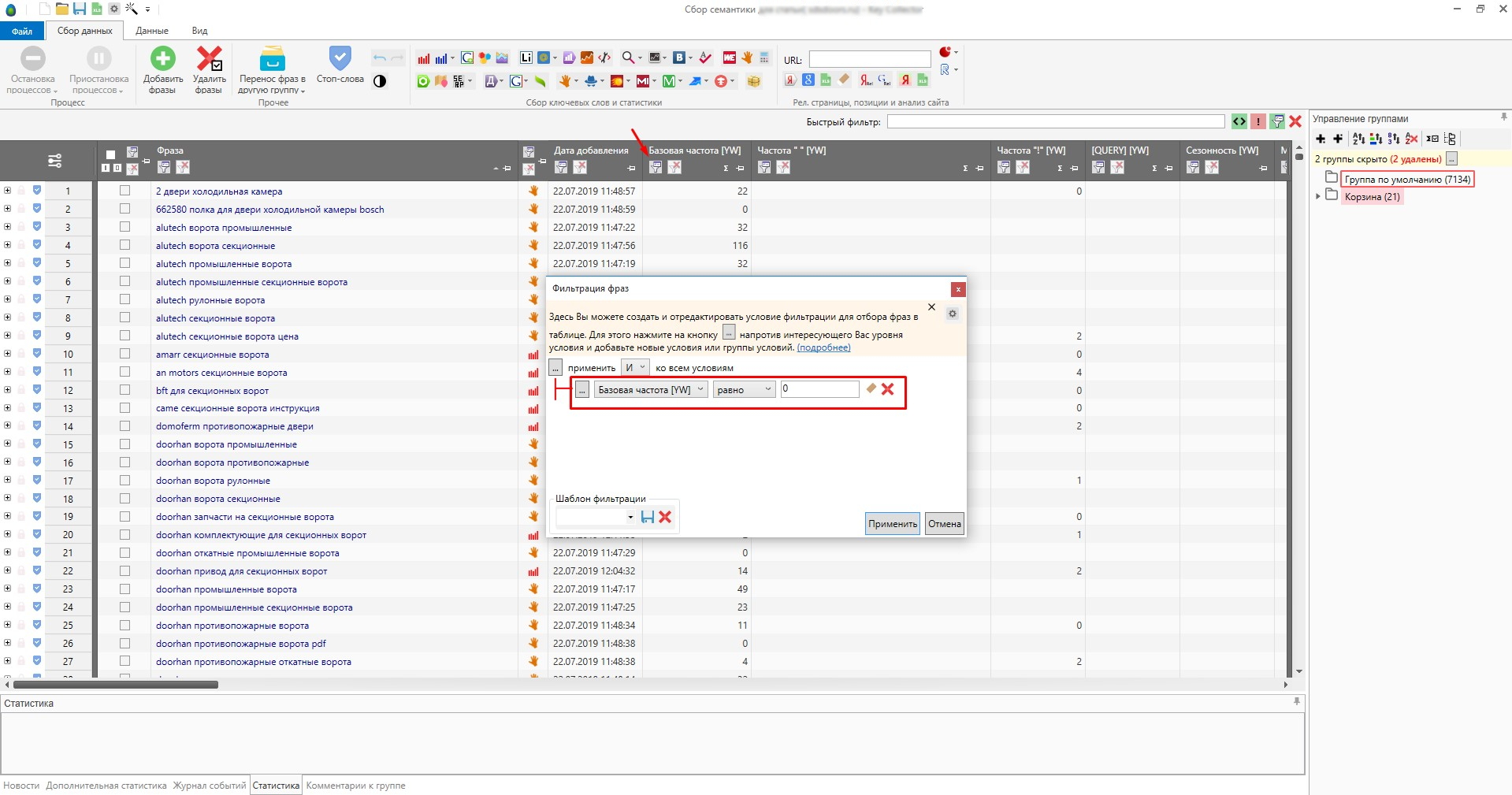
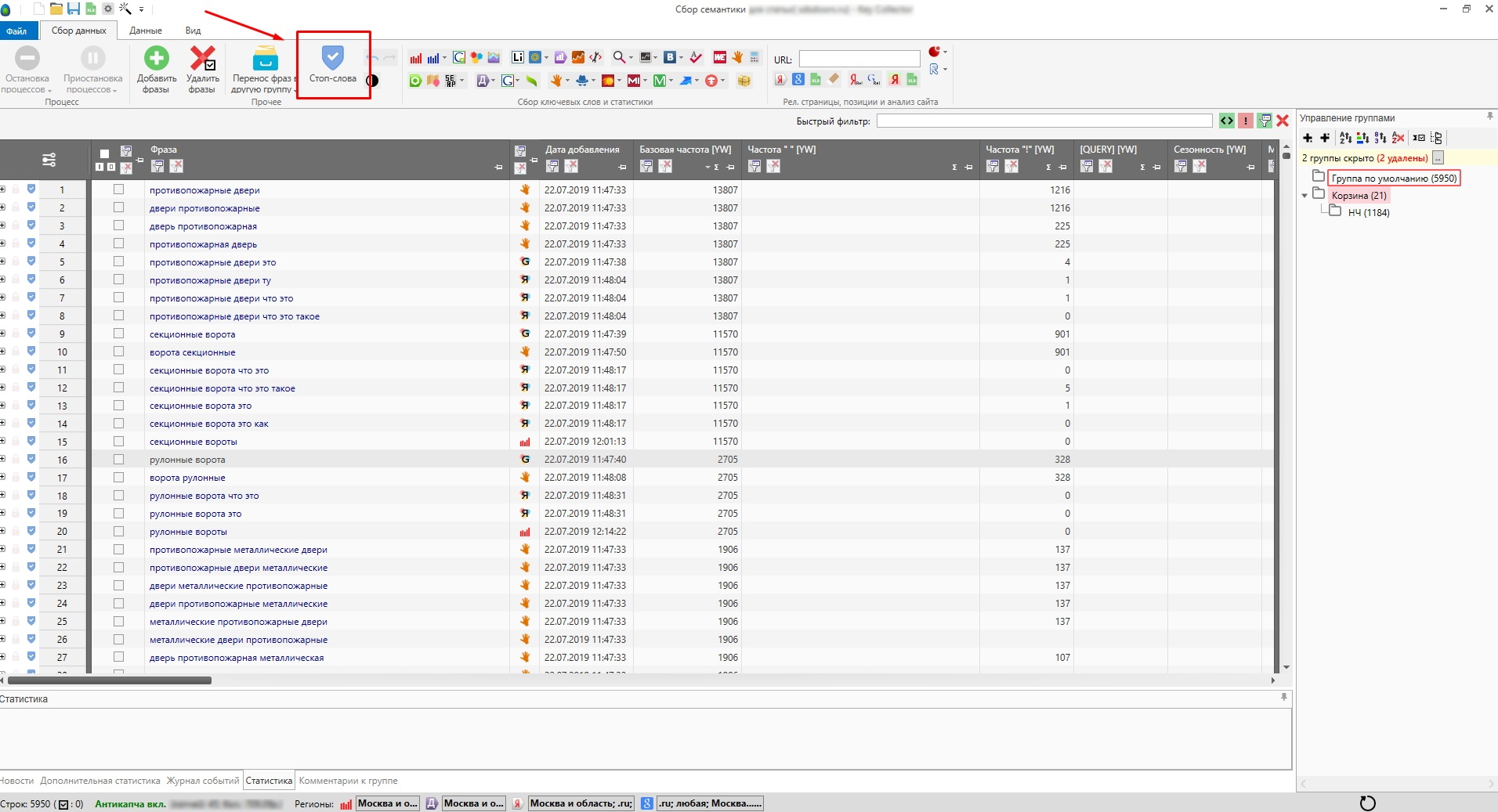
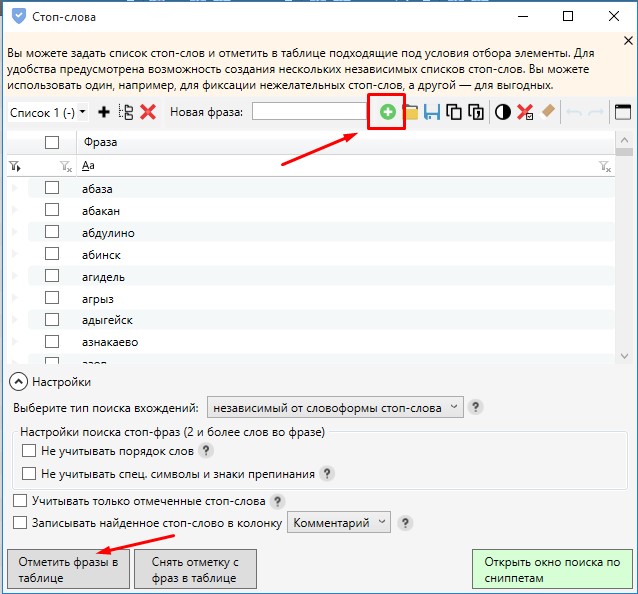
Я удаляю дубли с помощью частотности [QUERY], так как данный метод из множества дублей показывает наиболее правильную фразу, учитывая порядок слов по отношению к другим. К тому же у всех дублей точная частотность всегда одинаковая:
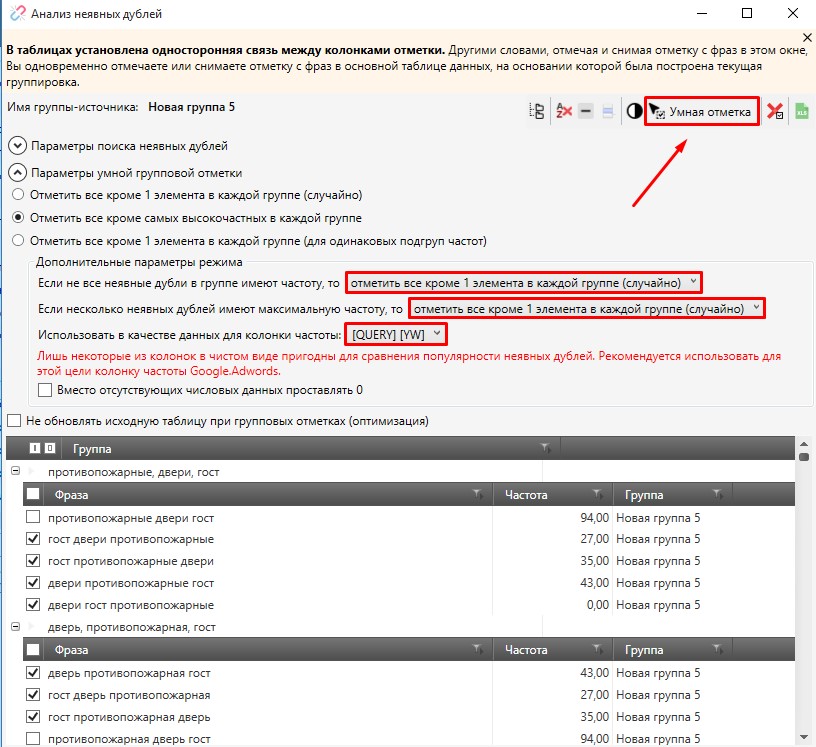
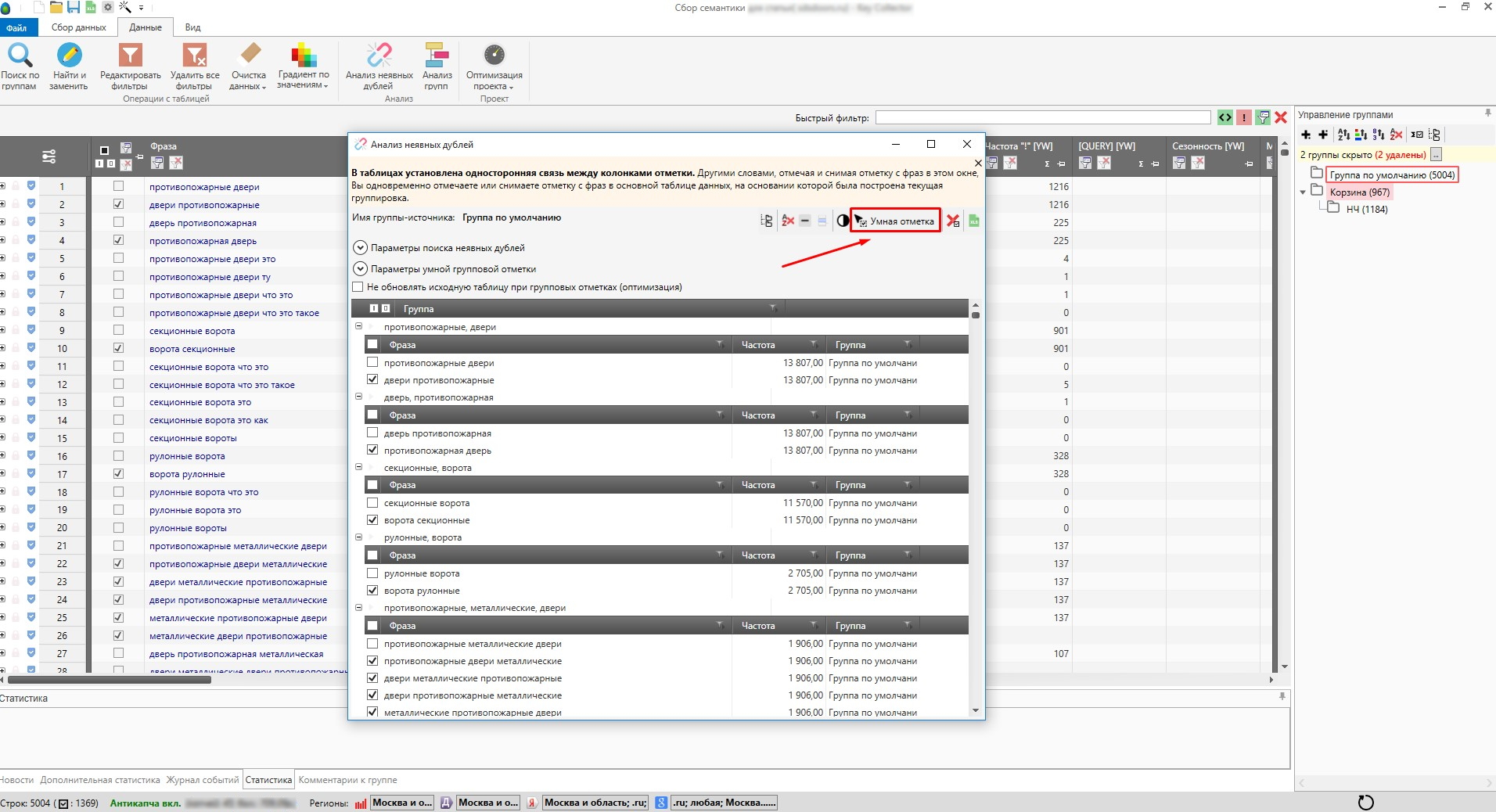
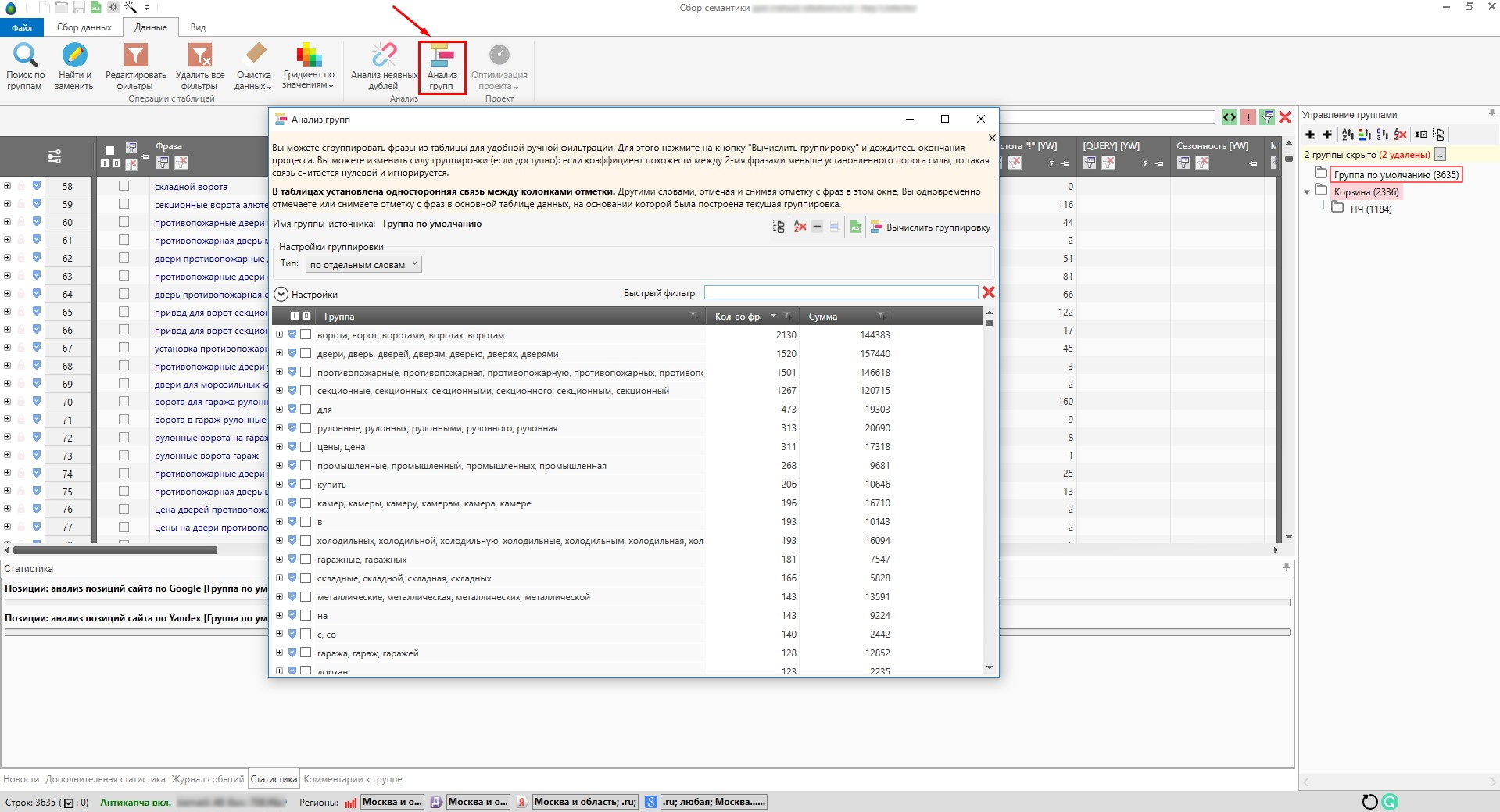
Здесь можно выделить кластеры, которые уже объединены по определенному слову и его вариации. Благодаря этому искать подходящие фразы из всего многообразия значительно легче.
Еще одним способ облегчения сбора необходимых слов в один кластер — ввод слова или фразы в строку быстрого фильтра:

Читайте также: