Как сделать репликацию
Добавил пользователь Евгений Кузнецов Обновлено: 10.09.2024
Репликация PostgreSQL представляет из себя способ реализации отказоустойчивого кластера. Инструкция написана на примере PostgreSQL 9.6 и 10, также она будет работать для PostgreSQL 9.2 (все нюансы будут отмечены отдельными комментариями).
В данном примере мы настроим потоковую (streaming) репликацию. Другой тип репликации (логическая) добавлена в PostgreSQL 10. Она позволяет реплицировать разные базы данных и таблицы на разные реплики.
Также, мы будем применять асинхронную репликацию — это вид репликации, при котором запросы выполняются сначала на мастере, затем попадают в журнал операций (WAL) и только после этого — на slave. При синхронной репликации запросы сначала попадают в WAL — после в мастер и слейв.
Используемые в данном руководстве команды, применимы для операционных систем Linux. Если Postgre работает под Windows, данную инструкцию можно использовать как шпаргалку для настройки конфигурационных файлов СУБД.
1. Подготовка серверов
Для начала, готовим наши серверы к настройке кластера.
PostgreSQL
На всех серверах баз данных должна быть установлена одна и та же версия PostgreSQL. Также, все серверы должны иметь одну и ту же архитектуру процессора.
Вот пример установки сервера PostgreSQL на CentOS 7.
Брандмауэр
При использовании брандмауэра, необходимо открыть TCP-порт 5432 — он используется сервером postgre.
а) Если управление выполняется с помощью Firewalld:
firewall-cmd --permanent --add-port=5432/tcp
б) Если используем Iptables:
iptables -A INPUT -p tcp --dport 5432 -j ACCEPT
в) Если используем UFW:
ufw allow 5432/tcp
SELinux
Если активирована система безопасности SELinux (по умолчанию в системах Red Hat / CentOS / Fedora), отключаем ее:
sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
Если необходимо, чтобы SELinux работал, настраиваем его.
2. Настройки на Master
В данной статье мы будем настраивать серверы с IP-адресами 192.168.1.10 (первичный или master) и 192.168.1.11 (вторичный или slave).
Переходим на сервер, с которого будем реплицировать данные (мастер) и выполняем следующие действия.
Создаем пользователя в PostgreSQL
Создаем нового пользователя для репликации:
createuser --replication -P repluser
* система запросит пароль — его нужно придумать и ввести дважды. В данном примере мы создаем пользователя repluser.
Выходим из оболочки пользователя postgres:
Настраиваем postgresql
Смотрим расположение конфигурационного файла postgresql.conf командой:
su - postgres -c "psql -c 'SHOW config_file;'"
В моем случае система вернула строку:
* конфигурационный файл находится по пути /etc/postgresql/9.6/main/postgresql.conf.
Открываем конфигурационный файл postgresql.conf.
* мы открываем файл, который получили sql-командой SHOW config_file;.
Редактируем следующие параметры:
listen_addresses = 'localhost, 192.168.1.10'
wal_level = replica
max_wal_senders = 2
max_replication_slots = 2
hot_standby = on
hot_standby_feedback = on
- 192.168.1.10 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации);
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации (данный параметр не нужен для postgresql 9.2 — с ним сервер не запустится);
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Открываем конфигурационный файл pg_hba.conf — он находитсяч в том же каталоге, что и файл postgresql.conf:
Добавляем следующие строки:
host replication repluser 127.0.0.1/32 md5
host replication repluser 192.168.1.10/32 md5
host replication repluser 192.168.1.11/32 md5
* данной настройкой мы разрешаем подключение к базе данных replication пользователю repluser с локального сервера (localhost и 192.168.1.10) и сервера 192.168.1.11.
Перезапускаем службу postgresql:
systemctl restart postgresql
* обратите внимание, что название для сервиса в системах Linux может различаться.
3. Настройки на Slave
Смотрим путь до конфигурационного файла postgresql:
su - postgres -c "psql -c 'SHOW data_directory;'"
В моем случае путь был:
Также смотрим путь до конфигурационного файла postgresql.conf (нам это понадобиться ниже):
su - postgres -c "psql -c 'SHOW config_file;'"
Останавливаем сервис postgresql:
systemctl stop postgresql
На всякий случай, создаем архив базы:
tar -czvf /tmp/data_pgsql.tar.gz /var/lib/pgsql/9.6/data
* в данном примере мы сохраним все содержимое каталога /var/lib/pgsql/9.6/data в виде архива /tmp/data_pgsql.tar.gz.
Удаляем содержимое каталога с данными:
rm -rf /var/lib/pgsql/9.6/data/*
И реплицируем данные с master сервера.
а) Если у нас postgresql 9:
su -u postgres -с "pg_basebackup -h 192.168.1.10 -U repluser -D /var/lib/pgsql/9.6/data --xlog-method=stream --write-recovery-conf"
* где 192.168.1.10 — IP-адрес мастера; /var/lib/pgsql/9.6/data — путь до каталога с данными.
б) Если у нас postgresql 10:
su - postgres -c "pg_basebackup --host=192.168.1.10 --username=repluser --pgdata=/var/lib/pgsql/10/data --wal-method=stream --write-recovery-conf"
* где 192.168.1.10 — IP-адрес мастера; /var/lib/pgsql/10/data — путь до каталога с данными.
После ввода команды система запросит пароль для созданной ранее учетной записи repluser — вводим его. Начнется процесс клонирования данных.
Открываем конфигурационный файл postgresql.conf на слейве:
И редактируем следующие параметры:
listen_addresses = 'localhost, 192.168.1.11'
* где 192.168.1.11 — IP-адрес нашего вторичного сервера.
Репликация — механизм синхронизации содержимого нескольких копий объекта. Под этим процессом понимается копирование данных из одного источника на множество других и наоборот.
- master - главный сервер, данные которого необходимо дублировать;
- replica - починенный сервер, хранящий копию данных главного
Для настройки репликации в MySQL необходимо выполнить ниже описанную последовательность действий, но это не догма и параметры могут изменяться в зависимости от обстоятельств.
На главном сервере отредактируем файл файл my.cnf, в секцию mysqld добавить строки:
- [master server id] - уникальный идентификатор сервера MySQL, число в диапазоне 2 (0-31)
- [dbname] - имя базы, информация о которой будет писаться в бинарный журнал, если баз несколько, то для каждой необходима отдельная строка с параметром binlog_do_db
На подчиненном отредактируем файл файл my.cnf, в секцию mysqld добавить строки:
На главном сервере добавим пользователя replication с правами на репликацию данных:
Заблокируем реплицируемые базы на главном сервере от изменения данных, программно или с помощью функционала MySQL:
Для разблокировки используется команда:
Сделаем резервные копии всех баз данных на главном сервере (или тех которые нам необходимы):
или средствами утилиты mysqldump :
Остановим оба сервера (в отдельных случаях можно обойтись и без этого):
Восстановим реплицируемые базы данных на подчиненном сервере с помощью копирования директории. Перед началом репликации базы данных должны быть одинаковы:
или функционала mysql, тогда mysql на подчиненном сервере не было необходимости останавливать:
Запустим mysql на главном сервере (а затем - на подчиненном, если это необходимо):
Проверим работы главного и подчиненного серверов:
На подчиненном сервере проверить логи в файле master.info, там должны содержаться запросы на изменение данных в базе. Так этот файл бинарный необходимо сначала преобразовать его в текстовый формат:
При возникновении ошибок, можно использовать команды:
и повторить все действия начиная с блокировки баз данных.
Для горячего добавления серверов репликации можно исользовать синтаксис:
Информация из статусов покажет позицию и имя текущего файла лога.
В случае асинхронной репликации обновление одной реплики распространяется на другие спустя некоторое время, а не в той же транзакции. Таким образом, при асинхронной репликации вводится задержка, или время ожидания, в течение которого отдельные реплики могут быть фактически неидентичными. Но у данного вида репликации есть и положительные моменты: главному серверу не надо беспокоится о синхронизации данных, можно блокировать базу (например, для создания резервной копии) на подчиненной машине, без проблем для пользователей.
Что такое репликация базы данных. Основные понятия и компоненты, типы репликации. Настройка репликации.
22 Янв 2021 12:01 IT GIRL 18
Репликация баз данных SQL: введение и настройка Блог 2021-01-22 ru Репликация баз данных SQL: введение и настройка
Репликация базы данных SQL
Объем данных в бизнесе, науке и разработке растет с каждой секундой. Практически все рабочие процессы связаны с использованием баз данных. Размеры БД в крупных компаниях не позволяют хранить их на физических дисках — слишком дорого и ненадежно. Безопаснее и удобнее использовать облачные хранилища и SQL-серверы.
Чтобы правильно организовать удаленный доступ, фиксировать изменения в данных и сохранять бэкапы, понадобится репликация. Что такое репликация базы данных , как ее настроить и что стоит учесть — рассказывают специалисты Boodet.Online.
Что такое репликация базы данных?
Репликация базы данных SQL Server — это особая технология копирования и распределения как самих данных, так объектов БД из одной базы в другую. Чтобы компоненты оставались целостными, нужна синхронизация. Репликацию можно сделать непрерывной или настроить на запуск через определенные промежутки времени.
Чем это отличается от обычного резервного копирования? Бэкапы — это просто информация. Например, резервная копия сервера — это данные о том, что на этом сервере было и как работало. Чтобы отладить процессы с помощью бэкапов, надо запустить восстановление. Репликация — это полностью готовый к работе клон главной базы данных . Если что-то идет не так, вы просто продолжаете работать, без каких-либо дополнительных действий. Когда главную БД починят, обновления тут же перенесутся с реплики. Чаще всего пользователи даже не замечают, что что-то произошло — процессы синхронизированы.
Репликация — одна из техник масштабирования баз данных.
Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
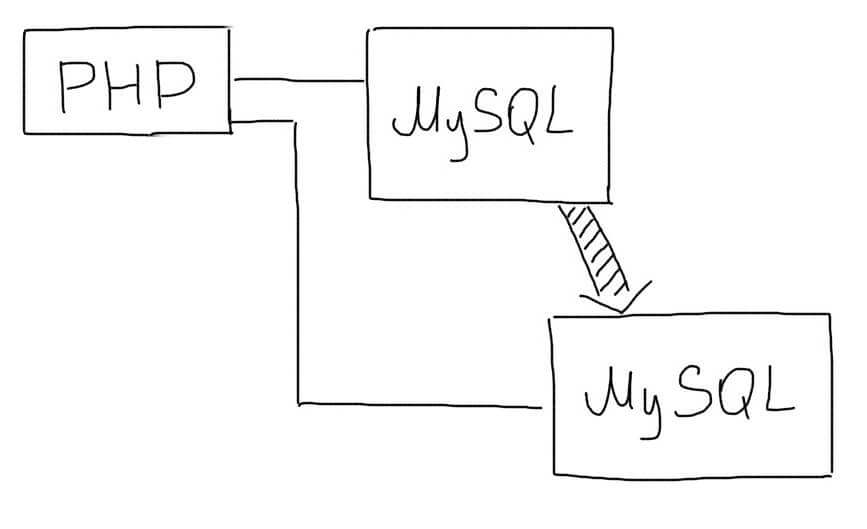
Существует два основных подхода при работе с репликацией данных:
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Master. На нем происходят все изменения в данных (любые запросы INSERT/UPDATE/DELETE ).
Slave сервер постоянно копирует все изменения с Master. С приложения на Slave-сервер отправляются запросы чтения данных (запросы SELECT ). Таким образом Master-сервер отвечает за изменения данных, а Slave за чтение.
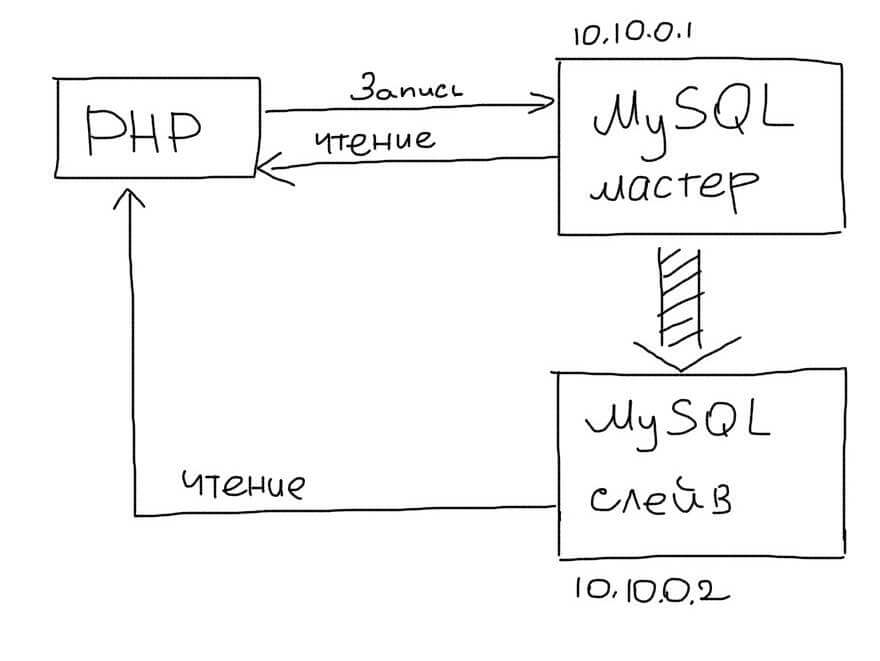
В приложении нужно использовать два соединения — одно для Master, второе — для Slave:
(Используем два соединения — для Master и Slave — для записи и чтения соответственно)
Несколько Slave серверов
Преимущество этого типа репликации в том, что мы можем использовать более одного Slave сервера. Обычно следует использовать не более 20 Slave серверов при работе с одним Master.
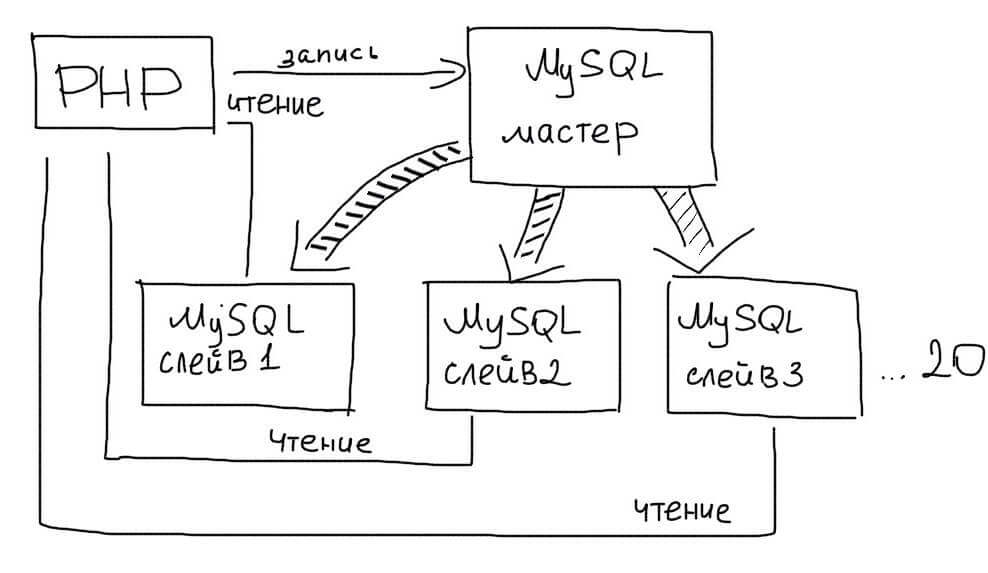
Тогда приложение выбирает случайным образом один из Slave серверов для обработки запросов:
Задержка репликации
Асинхронность репликации означает, что данные на Slave могут появиться с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Master, чтобы получить актуальные данные:
(При обращении к изменяемым данным, необходимо использовать Master-соединение)
Выход из строя
При выходе из строя Slave, достаточно просто переключить все приложение на работу с Master. После этого восстановить репликацию на Slave и снова его запустить.
Если выходит из строя Master, нужно переключить все операции (и чтения и записи) на Slave. Таким образом он станет новым Master. После восстановления старого Master, настроить на нем реплику, и он станет новым Slave.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Master сервер обрабатывает все запросы от приложения. Slave сервер работает в пассивном режиме. Но в случае выхода из строя Master, все операции переключаются на Slave.
Master-Master репликация
В этой схеме, любой из серверов может использоваться как для чтения так и для записи:
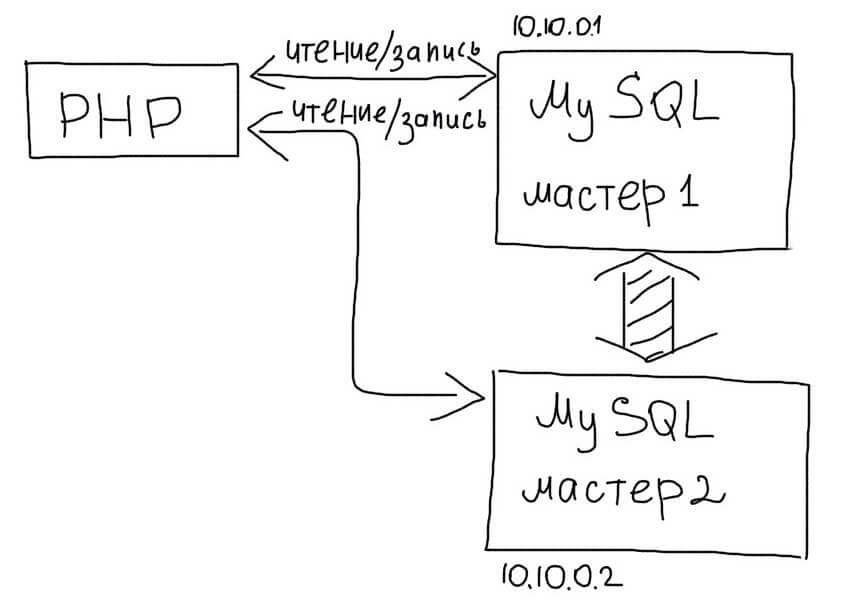
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Master серверов:
(Выбор случайного Master для обработки соединений)
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Slave.
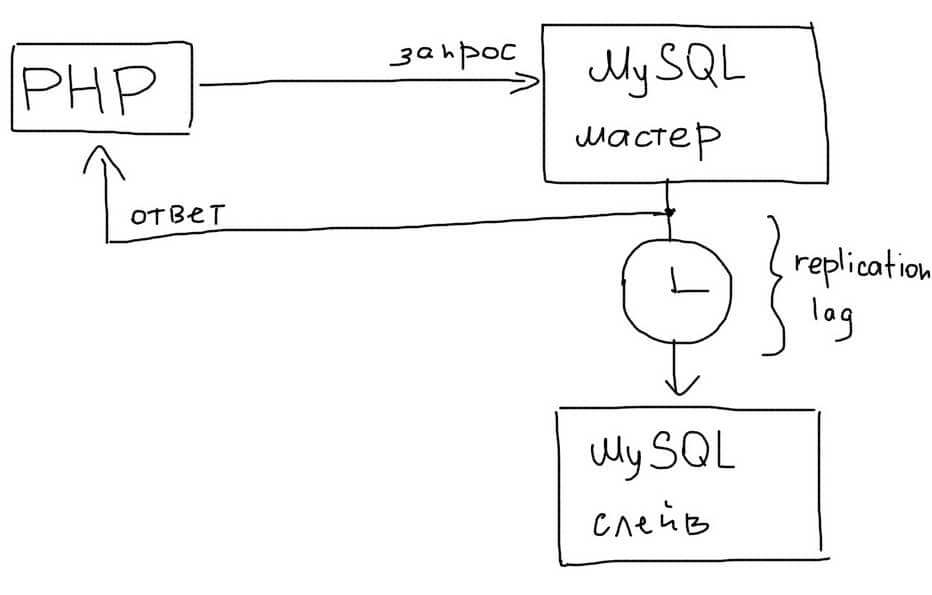
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Slave.
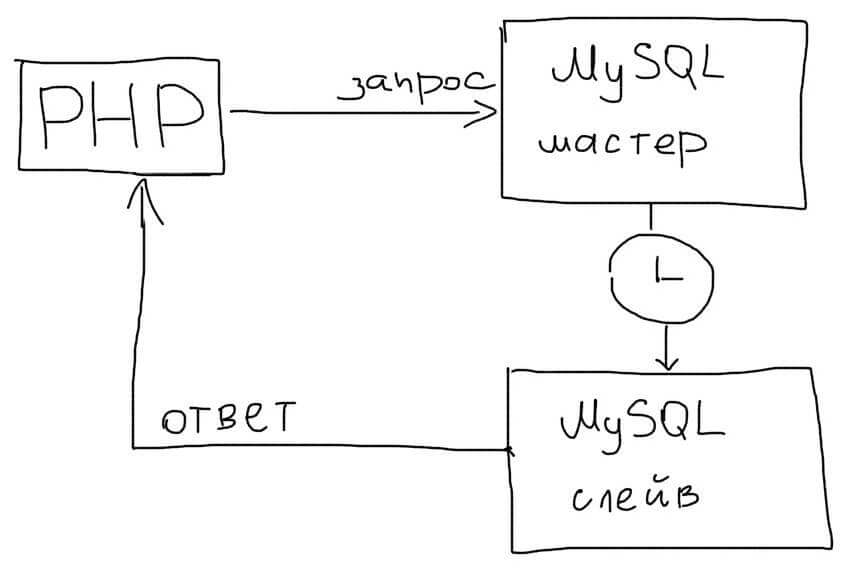
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Slave. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных:
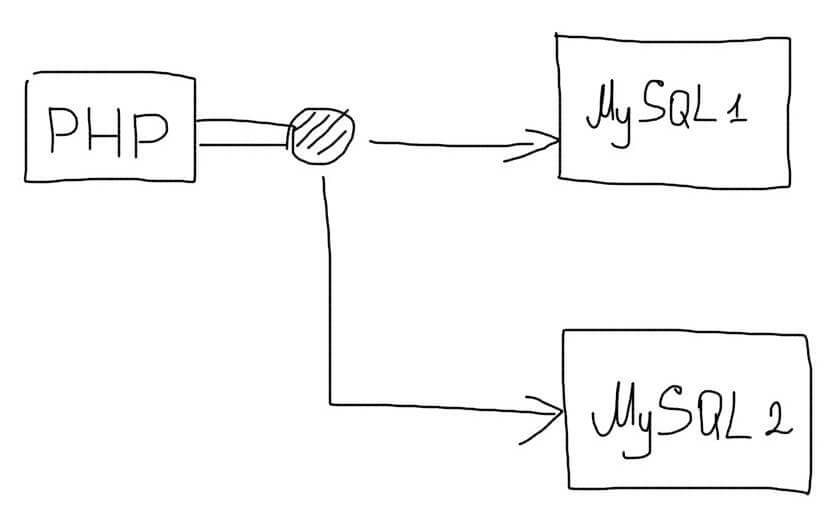
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
(Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном)
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
- Исключить сервер из списка используемых.
- Настроить репликацию Master-Slave на новом сервере, используя один из рабочих серверов в качестве Master.
- Когда все данные репликации будут синхронизированы, включить сервер обратно в список используемых и остановить репликацию.
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.

Читайте также: