Как сделать регистронезависимый поиск
Всем известно, что исполняемый код для платформы 1С не чувствителен к регистру символов. Некоторый особенные люди считают себя одаренными и пользуются этой возможностью, чтобы писать в своем уникальном стиле либо все маленькими буквами, либо наоборот большими. Оставим эти глупости на совести таких разработчиков, ведь нам же главное не "красота" в режиме конфигуратора, а чтобы обрабатываемые нами данные оставались аутентичными. Что бы "А" (код 1040) и "а" (код 1072) или "T" (код 84) и "t" (код 116) всегда оставались сами собой и превращались друг в друга только под нашим чутким контролем с помощью ВРег() и НРег(). К сожалению, бывает не всегда так, что может приводить к неожиданным ошибкам.
Предыстория
Как-то при переносе данных в одну животноводческую базу, я столкнулся со странным поведением выполнения довольно простого кода. У меня было множество животных с уникальными шифрами, описывающими их породу. Те, кто помнят школьные уроки по генетики, знают, что доминантные гены принято изображать большими буквами, а рецессивные - маленькими. Для остальных небольшая иллюстрация для понимания:
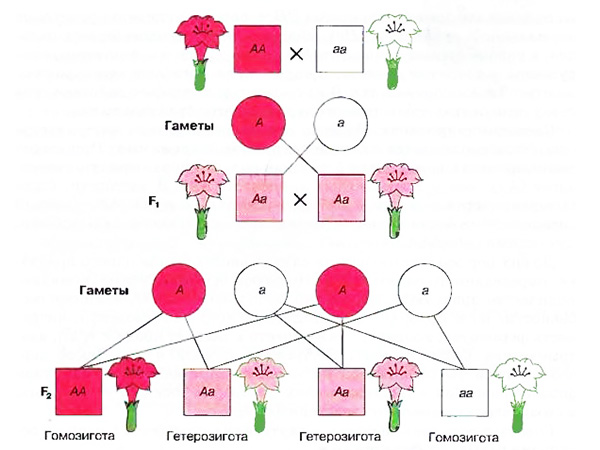
Казалось бы, что загрузку написал правильно, но результат в базе не соответствовал данным источника - данные по некоторым животным были перепутаны, а по части вообще ничего не загрузилось. Пристальное изучение несоответствий показало, что путаница наблюдались в тех случаях, когда шифры животных различались не составом, а только регистром.
Поиск по данным в базе
Давайте попробуем воссоздать пример с картинки выше и создадим справочник "Виды цветов" с тремя элементами: АА -> красный, Аа -> розовый и аа -> белый. Проблему можно увидеть сразу, если попытаться наш код внести в стандартное поле "Код":
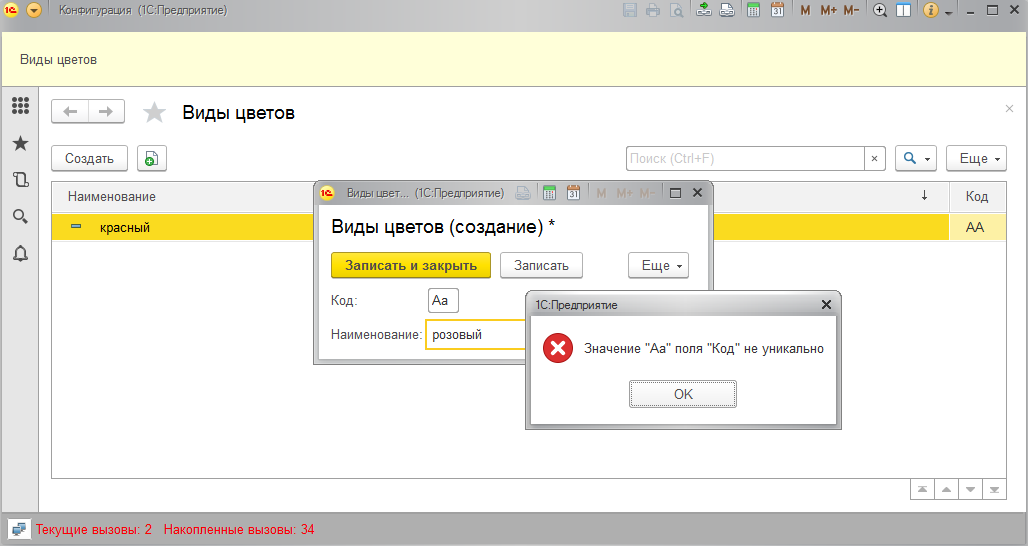
Заметим, что таким образом мы можем задать элементу справочника код А00001 и при автонумерации получим А00002, А00003 и так далее. Так же мы можем задать код а00001 и получить а00002, а00003. Но если мы при наличии А00001 по какой-то причине захотим установить номер а00001, то получить "облом".
Аналогичное поведение при тестировании кодов/номеров я обнаружел у документов, задач, бизнес-процессов, планов видов характеристик, планов счетов и планов обмена. Но у планов видов расчетов, однако, разрешается создать одновременно элементы с номерами "А00001" и "а00001", что очень странно - тут можно было бы сослаться на то, что у плана видов расчетов в настройках отсутствует свойство включения/отключения контроля уникальности номера, но этого свойства так же нет и у плана обменов. В документации о такой выборочно действующей особенности поведения ничего не написано. Если я просто не увидел, то напишите в комментариях.
Кстати, поскольку удалось создать несколько видов расчета с идентичными кодами, то это прекрасный повод проверить результат функции НайтиПоКоду(). Только предварительно я воспользуюсь отсутствием у плана видов расчетов контроля уникальности номеров и добавлю еще один элемент с большой "А" - интересно какой из этих двух элементов будет выбран:
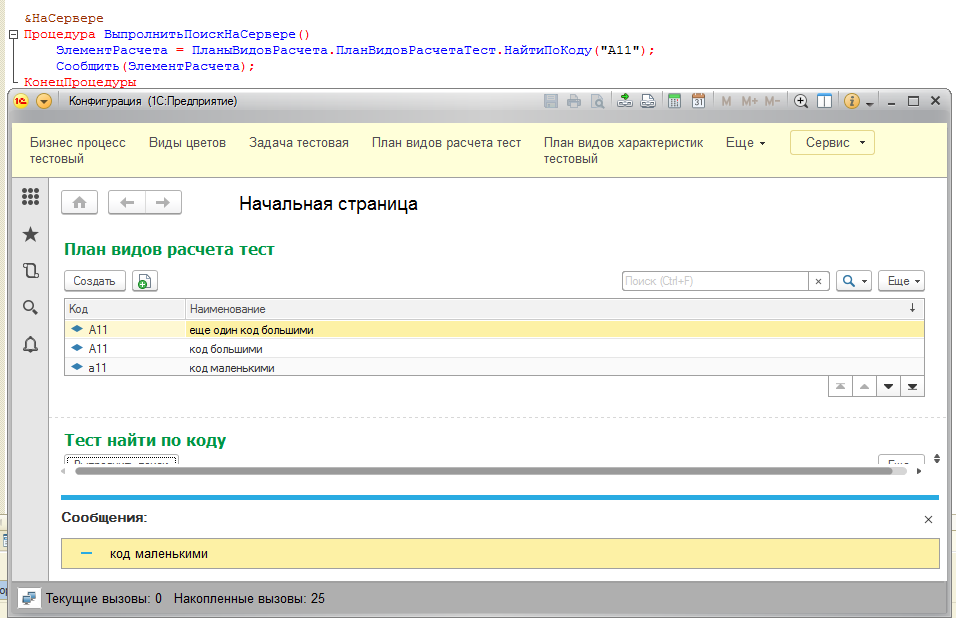
Да, уж. Согласитесь, результат оказался неожиданным и он подтверждает ранее замеченное наблюдение, что для платформы 1С регистр символов как минимум в кодах/номерах значения не умеет. Выходит, создавая код на нашей платформе, программист получает по факту выполнения: 1040 = КодСимвола("А") = КодСимвола("а") = 1072 , и лишь конечный пользователь системы видит на экране реальные символы.
Но продолжим нашу проверку. Обычно на практике для всяких внешних кодов используют реквизиты - в моем случае было так же. Создадим такой для справочника "Виды цветов" и попробуем воспользоваться другим стандартным поисковым методом - НайтиПоРеквизиту():
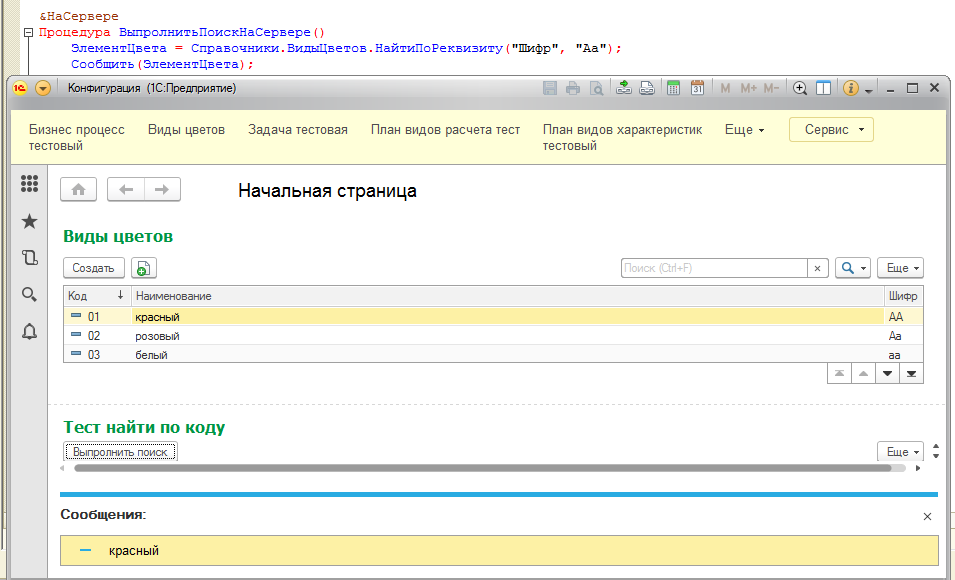
Как раз с этим я и столкнулся при переносе - в поиске по реквизиту регистр символов игнорируется.
Хотя, как оказывается, не обязательно быть программистом, что бы испытать дискомфорт при точном поиске - аналогичное поведение наблюдается и при использовании отборов СКД в динамическом списке (видимо одна и та же поисковая функция из внутренней библиотеки):

Для полноты картины, давайте протестируем последний оставшийся метод - ПоискПоНаименованию() и получим тот же результат (даже требование "точного соответствия" не помогло):
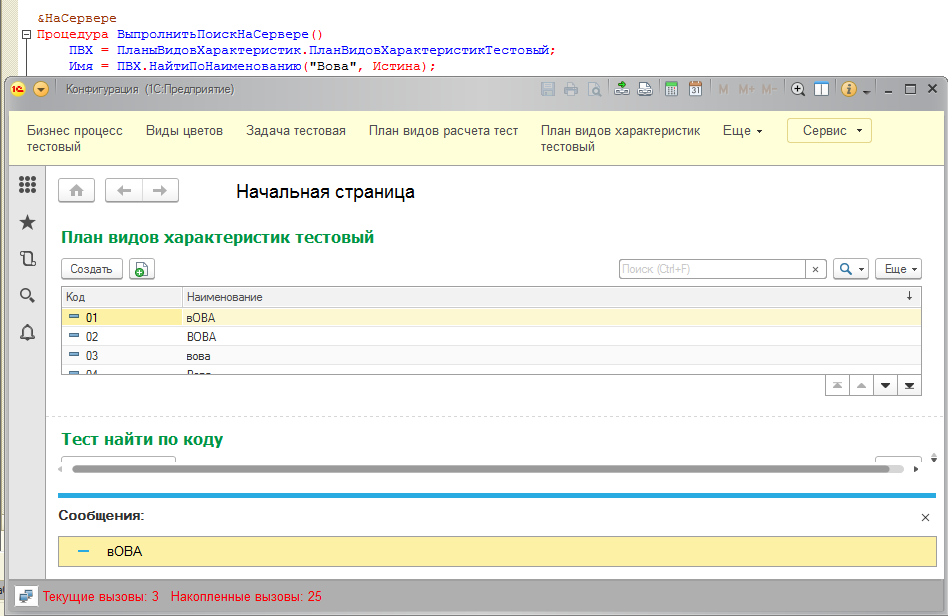
Итак, поисковые методы менеджеров объектов отказываются правильно искать чувствительные к регистру символов данные. А можно ли самостоятельно создать подобные методы с помощью механизма запросов? Давайте попробуем:
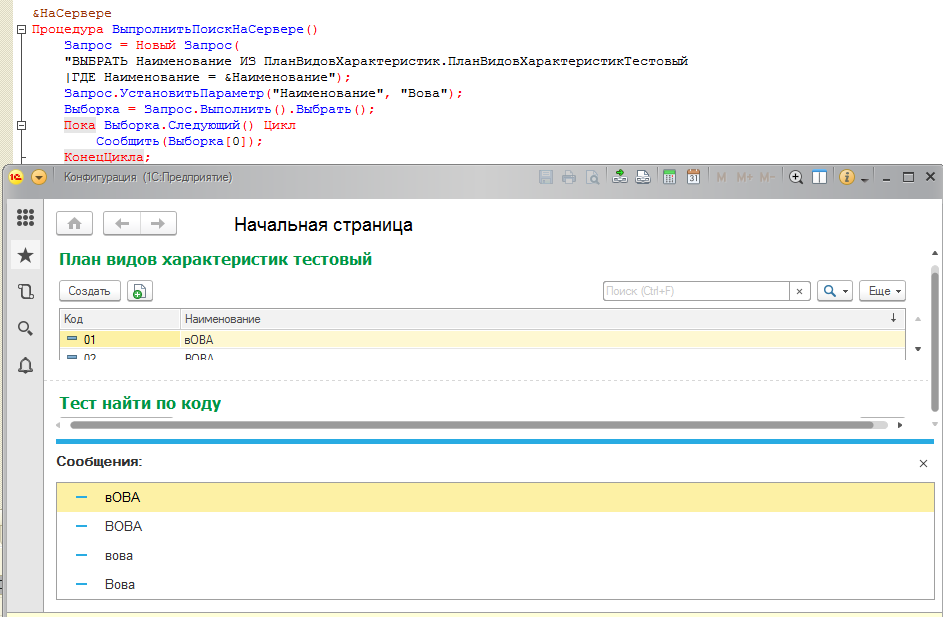
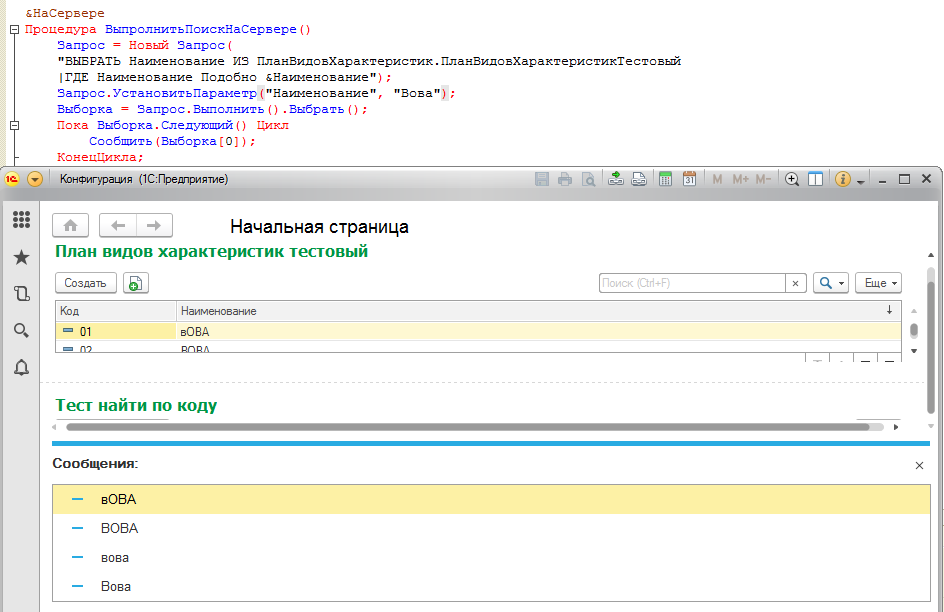
Как видите, ни использования оператора "=" в тексте запроса, ни оператор "Подобно" не помогли - каждый раз выбираются все похожие элементы, игнорируя регистры символов.
Т.е. для текста запроса, который транслируется в SQL и выполняется во внешних СУБД, снова верно выражение: 1040 = КодСимвола("А") = КодСимвола("а") = 1072. Я уже приготовился, что все во что я верил ложно и в мире 1С будет справделиво ("А" = "а") = Истина, но к счастью хотя бы примитивное сравнение строк работает и нужную нам функцию все же можно создать:
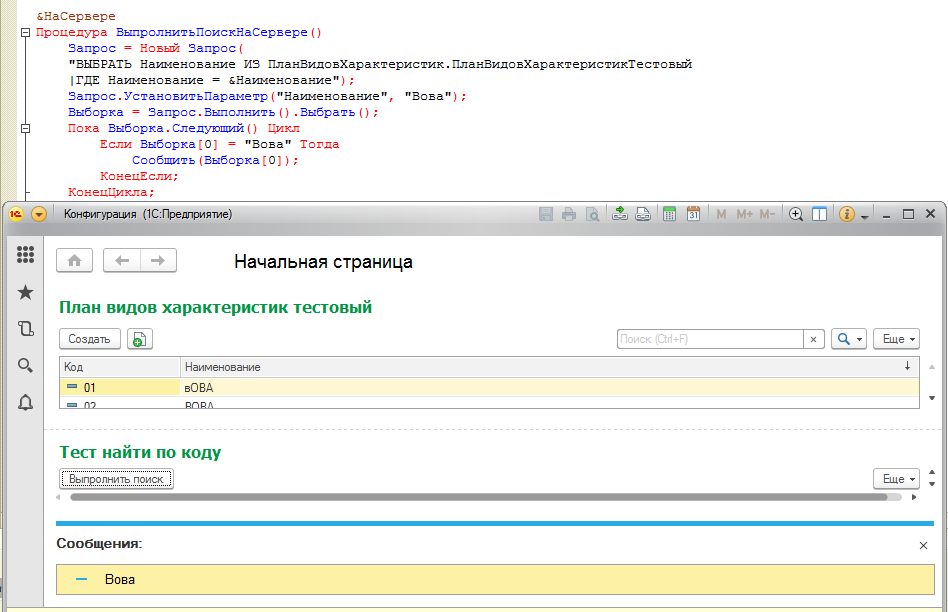
Поиск по коллекциям
С данными базы как мы уже убедились - грустно. А как дело обстоит с коллекциями?
Массив - обнаружена чувствительность к регистру символов в обычном и фиксированном вариантах для метода Найти().
Таблица значений - методы Найти() и НайтиСтроки() чувствительны к регистру.
Список значений - метод НайтиПоЗначению() чувствителен к регистру символов.
Структура - поисковые методы отсутствуют, а ключи регистр игнорируют.
И если требуется в модуле менеджера, что бы выводить поле в представление или что бы подбор с регистром работал
(11) для поля наименования покатит (если представление по наименованию) и в динамических списках выводить не Наименование, а Ссылка. А что с реквизитами? На формах списков/выборов писать варианты ПриПолученииДанных (для ОФ и УФ по разному) и делать функции общих модулей для расчета представления полей в отчетах на компоновке? Как-то уж слишком большая цена за возможность регистрозависимого поиска - дешевле в модуле менеджера справочника дописать свою поисковую функцию.
А что с реквизитами? На формах списков/выборов писать варианты ПриПолученииДанных (для ОФ и УФ по разному
Зачем вообще такой реквизит нужен, если по нему не делается ввод по строке? Или не делается поиск в формах списка/выбора? Искать по наименованию в модулях? Я промолчу, что я об этом думаю.
Считывание лишних данных всегда дороже. К тому же отсутствие возможности создания поиска в формах списка/выбора.
А как сделать так, чтобы отборы СКД и динамических списков у пользователей "чувствительно" отрабатывали?
(17) к счастью, класс задач с чувствительностью к регистру не очень широкий.
В тех случаях, когда нужно на формах делать регистрочувствительный фильтр - нужно делать этот фильтр самому. В зависимости от данных есть разные пути. Для небольшой выборки, когда отклонений много - запросом и повторным сравнением отобрать нужные ссылки и наложить на динамический список отбор по Ссылка ВСписке. Если выборка большая и мало отклонений - оставить Реквизит Равно/Подобно/Содержит, а с помощью функции отобрать именно отклонения для второго условия отбора - Ссылка НеВСписке.
(18) Широкий-неширокий, но я вот с такой столкнулся сегодня:
В ftp-папке ищу по маске "*.pdf" файлы и не нахожу, а выясняется, что у них всех расширение "*.PDF". И получается, чтобы найти все PDF файлы в папке нужно сначала искать так:
FTPСоединение.НайтиФайлы("*.PDF");
потом так:
FTPСоединение.НайтиФайлы("*.pdf");
а для верняка потом ещё так, так и так:
FTPСоединение.НайтиФайлы("*.Pdf");
FTPСоединение.НайтиФайлы("*.pDf");
FTPСоединение.НайтиФайлы("*.pdF");
FTPСоединение.НайтиФайлы("*.PdF");
По мне - так это глумление над разработчиком.
В описании функции ни слова о чувствительности к регистру:
FTPСоединение (FTPConnection)
НайтиФайлы (FindFiles)
Синтаксис:
Тип: Строка.
Путь к каталогу, в котором производится поиск. При использовании этой схемы в адресах необходимо указывать прямые слеши '/', а не обратные '\'.
Допускается указание полного имени файла (путь + имя).
(необязательный)
Тип: Строка.
Маска выбора файлов. В строке маски допускается использование символа "*" (звездочка), обозначающего любое число произвольных символов, и "?" (знак вопроса), обозначающего один произвольный символ.
Если параметр задан, то первый параметр воспринимается системой как путь к каталогу, в котором требуется найти файлы, удовлетворяющие маске выбора.
Можно ли с помощью REGEXP осуществлять регистронезависимый поиск?
name
ЯБЛОКО
ЯБлоКо
SELECT * FROM table WHERE name REGEXP 'яблоко';
Как сделать чтобы искалось яблоко во всех регистрах?
Хотелось бы знать можно ли это сделать сразу в регулярном выражении REGEXP, без использования до запроса php, strtoupper()
Как вариант нашел что можно так сделать:
SELECT * FROM table WHERE name REGEXP UPPER('яблоко');
Но все же, есть ли в mysql REGEXP, как и в php, такое же /i правило?
name
ЯБЛОКО
ЯБлоКо
SELECT * FROM table WHERE name REGEXP 'яблоко';
Как сделать чтобы искалось яблоко во всех регистрах?
Хотелось бы знать можно ли это сделать сразу в регулярном выражении REGEXP, без использования до запроса php, strtoupper()
UPPER = это верхний регистр
lower = нижний регистр
смотрите пример , вам надо lower
СУБД MySQL как вы хотели
| REGEXP is not case sensitive, except when used with binary strings. |
Если бы архитекторы строили здания так, как программисты пишут программы, то первый залетевший дятел разрушил бы цивилизацию
А regexp в мускуле разве регистрозависимый? Вот смотрю
да, регистронезависимый. Возможно есть нюансы из-за причин данной регистронезависимости, может влияние utf-8 или еще чего. Но вот смотрите на скрин:

SELECT * FROM lower2 WHERE name REGEXP('яблоко');

SELECT * FROM lower2 WHERE name='яблоко';
+xxbesoxx Конечно спасибо, но твой вариант не подойдет ибо простой запрос where и так в моем случае ищет в любом регистре и без lower. А мне нужно обязательно регулярное выражение, так как условий в поиске очень много в моем запросе, единственное чтобы хотелось это регистронезависимость использовать.

Думаю что надо так, и все работает:
SELECT * FROM lower2 WHERE lower(name) REGEXP lower(('яблоко'));
Последний раз редактировалось Microplankton; 03.03.2015 в 10:28 . Причина: изменено изображение запроса sql
Если бы архитекторы строили здания так, как программисты пишут программы, то первый залетевший дятел разрушил бы цивилизацию
Периодически мы сталкиваемся с проблемой, что в SQlite по умолчанию оператор LIKE регистрозависим.
Как же выйти из положения?
Причем стандартные решения не подходят.
Но мы нашли простой и действенный метод! Работает на любых хостингах!
Шаг1: задаем новую функцию (можно в конструкторе прописать)
$this->dbh->sqliteCreateFunction('U_LOWER', "u_strtolower", 1);
Шаг2: пишем SQL запрос
$sql = "SELECT * FROM items WHERE u_lower(name) LIKE ('%". mb_strtolower($search) ."%') ";
где видно, что мы:
добавили свою функцию к полю name u_lower
добавили mb_strtolower
Таким образом перевели в нижний регистр все!
Кстати если функции нет, то ее можно создать (и нужно):
if (!function_exists('u_strtolower')) <
function u_strtolower($str) <
return mb_strtolower($str, 'UTF-8');
>
>

02.07.21 Базы данных 403
Выбор данных из базы данных (БД) является обычной частью работы любого современного приложения. В большинстве случаев достаточно получать данные без учета регистра, именно таким способом и работает большинство баз данных, что позволяет повысить производительность.

Однако, как быть в случаях, если необходим именно выбор данных из БД с учетом регистра? Данная проблема актуальна для недвоичных строк (VARCHAR, TEXT, CHAR и т.д.), тогда как для данных в двоичном виде происходит обработка с учетом регистра (BLOB, BINARY и прочие типы).
Для решения подобной задачи можно прибегнуть к нескольким способам:
– использовать команду BINARY для двоичной обработки данных. В таком случае будет происходить обработка данных в двоичном виде. Пример запроса: SELECT * FROM `table` WHERE BINARY `column` = 'value';
– использовать кодировку базы данных с учетом регистра, сопоставление носит название, оканчивающее на _cs или _bin. Скорее всего этот способ не подойдет для большинства случаев, так как никто не станет менять кодировку всей базы данных из-за одной операции с потребностью обрабатывать данные с учетом регистра;
– использовать в запросе команду с явно указанной кодировкой для конкретного запроса, но возможны ошибки, если указанной кодировки нет на сервере БД. Пример запроса: SELECT * FROM `table` WHERE `column` COLLATE latin1_general_cs = 'value';
– использовать специальные SQL команды UPPER или LOWER, но это может отразиться на производительности в случае большого количества данных. Пример запроса: SELECT * FROM `table` WHERE LOWER(`column`) = LOWER('value');
– использовать приведение регистра в коде и после чего выполнять запросы, для этого могут быть использованы функции наподобие mb_strtolower, mb_strtoupper и т.д.;
– использовать логику в своем коде для фильтрации строк с разным регистром. Это означает что сначала выбираются все необходимые данные, удовлетворяющие заданным критериям, после чего происходит дополнительная проверка регистра в коде, например, в PHP.
Последние два способа могут оказаться не самыми производительными для большого набора данных. Такой подход подойдет не для всех случаев, так как рекомендуется использовать средства БД для большей производительности.
Были рассмотрены некоторые приемы для работы с базой данных с учетом регистра. Аналогичные методы работы можно применять и для операций обновления и удаления данных, то есть для команд UPDATE и DELETE.

Читайте также: