Как сделать обработку голоса в реальном времени
Добавил пользователь Дмитрий К. Обновлено: 29.08.2024
Лучшие топовые программы для изменения голоса. Подборка забавных программок, способных изменить ваш голос до неузнаваемости. Хотели бы вы разговаривать, как Владимир Жириновский, а может быть, как мультяшный персонаж или просто как представитель противоположного пола?
Вопросы:
Пожалуй, самое простое, и при этом бесплатное приложение для изменения голоса в реальном времени. Оно не требует установки и едва ли дотягивает до 50 килобайт. Для его использования достаточно микрофона.
Последний релиз Funny Voice 1.4 датирована 2016 годом, программа работает на Windows 10 и младших версиях операционной системы.
В меню вы сможете обнаружить 26 эффектов по мутации голоса. К имеющимся шаблонам можно добавить любой эффект в формате VST (поищите в Интернете) или же создать собственный, воспользовавшись встроенным редактором.
Кроме того, Scramby предлагает фоновые звуки наподобие шума толпы и прибоя, лая собак или рёва мотоциклов. Их список также можно расширить, добавив (или записав) mp3-файл.
Выпущенная в 2015 году Scramby 2.0, обновляется редко, последняя версия 2.0.60.0 датирована 2018 годом.
Что же касается операций с голосом, то к нашим услугам множество эффектов, включая изменение голоса в скайпе на женский. Перед тем как сделать выбор, можно потренироваться - разработка предусматривает чат с интеллектуальным роботом. В дополнение софт предлагает фоновую музыку во время разговоров.
Несмотря на солидный возраст, программа до сих пор популярна. Обновление с драйверами для Windows 10 вышло в 2018 году.
AV Voice Changer Diamond многими экспертами признана как лучшая программа для изменения голоса. Её функционал действительно впечатляет. Тонкие настройки, по словам разработчиков, способны помочь даже в соблазнении противоположного пола. К примеру, во время звонка с компьютера, вы можете сделать свой голос до неприличия томным и сексуальным.
Кроме того, вы сможете добиться изменения голоса в Скайпе на женский (если вы - мужчина, разумеется, и наоборот). Записать плоды своих трудов также возможно. К слову, софт работает не только в реальном времени, его разрешается применять и к записям, в том числе песням (при этом меняется только вокал), сохраненным беседам и так далее.
AV Voice Changer Diamond располагает множеством эффектов. Особенно интересен Voice Comparator, при помощи которого можно подделывать голоса знаменитостей. Но даже если этого вам будет мало, можно загрузить еще фильтров с сайта разработчиков. Обидно только, что бесплатная версия работает всего 14 дней.
Эта программа предназначена для обработки уже записанного голоса. Она поможет вам изменить тембр, поднять тональность на пару октав или понизить (повысить) запись всего на полтона. Такие манипуляции могут понадобиться вокалистам или дикторам, а также тем, кто озвучивает обучающие или развлекательные видеоролики. Кроме того, разрешается ускорять или замедлять скорость воспроизведения.
Сохранить готовый вариант предлагается в формате WAV.
AthTek Free Voice Changer 1.5 появилась в 2016 году. В связи с выходом десятой версии OS Windows, разработчики выпустили обновление в 2018 году, с тех пор программа не обновлялась.
Fake Voice – это удивительно простая в интерфейсе программка, которая обладает впечатляющим функционалом. С её помощью вы сможете говорить так, что вас едва ли узнают друзья или родственники. Использовать приложение можно как при общении по мессенджеру через веб-камеру, так и во время онлайн-игры. Меняйте голос с мужского на женский, говорите, как пришелец или как пьяный деревенский парень, упавший в колодец. И всё это настраивается всего лишь в пару действий.
Еще одно приложение, работающее со Skype. Запустите Скайп, а затем VOICEMASTER и предоставьте последнему доступ к программе для общения. После этого вы сможете изменять высоту тона и придавать голосу разные оттенки в специальном окошке. Всё это можно применять в режиме реального времени, но прежде разрешается испробовать тестовый режим.
Программа для изменения голоса в режиме реального времени. На выбор предлагается несколько шаблонных вокальных эффектов: мальчик, робот, девочка, инопланетянин, женщина, варвар. С помощью настроек можно усилить, исказить, повысить или понизить тон аудиозаписи. Программное обеспечение совместимо с играми Steam, CS GO, Call of Duty: Warzone, Rainbow Six Siege, Apex Legends, Discord, онлайн-радио, мессенджерами. Можно создать несколько последовательных шаблонов модификаций и сохранить эту цепочку в файле настроек, чтобы позже загрузить ее для новой аудиодорожки.
Дополнительные эффекты: эхо, улица, дождь, гром, камин, молния, звуки колокола. Полученные эффекты можно применить уже к записанным файлам, онлайн или вывести на динамики, чтобы прослушать перед сеансом связи. Программа нетребовательна к ресурсам и практически не нагружает центральный процессор. Софт предоставляется бесплатно для некоммерческого домашнего использования. Программу можно устанавливать на операционные системы семейства Windows, MacOS.
Почти все ПО, попавшее в рейтинг, разрабатывалось более 10 лет назад. Если в описании не отмечено, что программа работает только со Skype, она будет изменять голос в любом приложении Windows.
Комментарии
Наконец-то я нашла для веселого времяпровождения программу по изменению голоса.
Я нашла идеальную программу для изменения голоса !)
А теперь всё по порядку
Funny Voice - здесь просто без комментариев. Непонятно, зачем оно тут в списке.
Scramby - наихудшее качество из всех перечисленных программ. Отвратительно всё, начиная с оформления и заканчивая некачественным изменением голоса.
MorphVox JR - максимум, что можно выжать из неё, так это только голос ШколоСахара. Ничем не отличается от Pro версии с никуда не годным эквалайзером. Такая программа недостойна денег.
Clownfish - максимум, что можно сделать, это придуриваться в скайпе. Исключить из списка немедленно.
Voice Changer Diamond - единственная годная программа в списке. Изменять голос с помощью неё мешает только русский акцент говорящего.
Skype Voice Changer - не пробовал, но если она в этом топе, то вряд ли вообще что-то может
AthTek - вот это реально непонятно что, нет качества, невозможно создать красивый голос, исключить из списка.
Fake Voice - оценка 8.3? Вы серьёзно? Вы 8 с 0 не перепутали? О каком функционале идёт речь, если его там вообще нет?
VoiceMaster - аналогично с FakeVoice, но как и в остальных, можно исковеркать голос, но не изменить его.
Voxal - мало того, что драйвера у этой программы несовместимы с микрофонами Genius, так ещё вместо изменения голоса у вас получится только . (даже матом описать не получится). Страшно то, что Voxal ещё кто-то нахваливает и рекомендует.
VoizGame - аналогично Diamond'у (они от одного разработчика - Avnex), но намного хуже. В отличие от предыдущего мусора, может хотя бы обработать голос (например удалить шум и сделать звучание лучше), но опять же, не способен изменить его.
В списке можно оставить только Diamond, да это единственная программа, изменяющая голос за 7000 рублей. Не понимаю КАК всё остальное попало в этот топ?
У каждого своё видение того как должна выглядеть программа, а тем более Топ программ.
AV Voice Changer Diamond это, по мне, ерунда полнейшая. Говоришь в микро, получается икание какое то. Вот Voxal Voice Changer - другое дело. Единственная рабочая программа. Даже если шёпотом говорить, работать будет на ура.

Голос до обработки
Начнем, с того, что запись осуществляется не в студийных условиях, а в кабинете, где стоит несколько системных блоков и кондиционер — конечно же все они очень шумят и создают помехи в записи. Если кондиционер еще можно выключить, то самый шумный системник, по стечению обстоятельств мой, выключить нельзя — иначе как записывать :-). Сразу хочу предупредить, что из-за этих условий избавиться от всех шумов не удастся, но при условии, что на трек будут наложены эффекты, типа эхо и реверберация, а фоном будет служить музыка, недостатки будут незаметны.
Микрофон: Perception 120.
Задача: Записать голосовое сопровождение для некоего ролика и наложить его на музыку. В качестве примера буду приводить отрывок.
Записанный трек звучит следующим образом:
Пошаговая обработка голоса
1 шаг. Откроем трек в программе Adobe Audition.
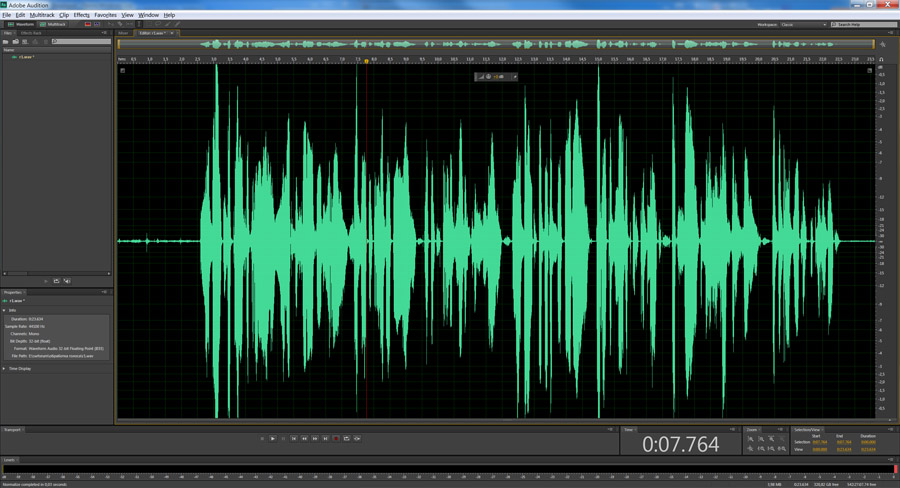
Трек будет выглядеть вот так:
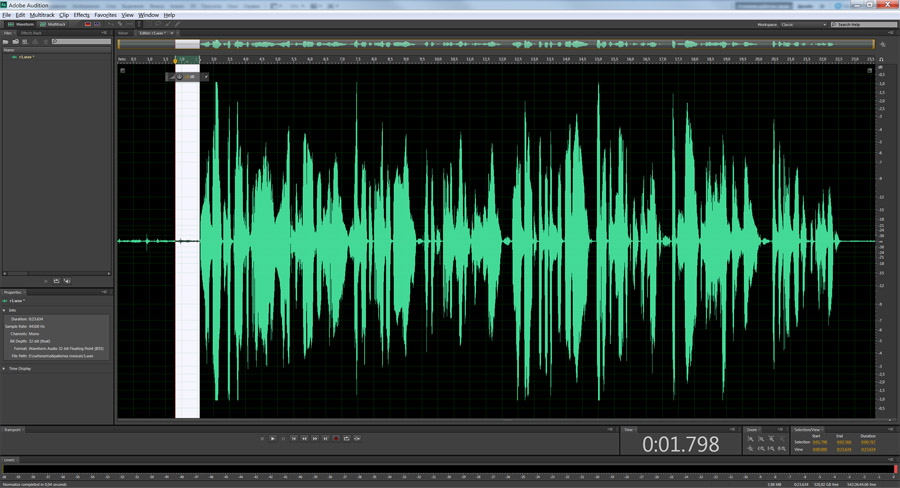
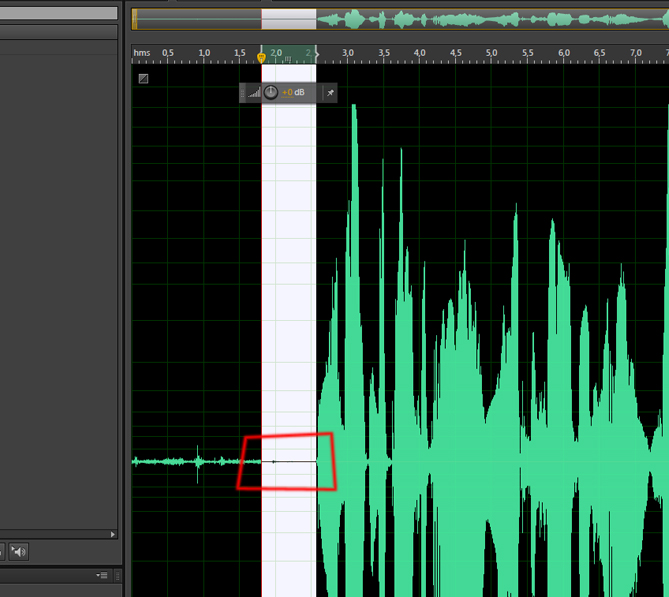
3 шаг. Избавимся от шумов. Для этого, пользуясь указателем мыши, выделим на треке небольшой кусочек шума, как здесь:
Вызовем пункт меню Effects — Noise Reduction / Restoration — Noise Reduction (process) . Появится следующее диалоговое окно:
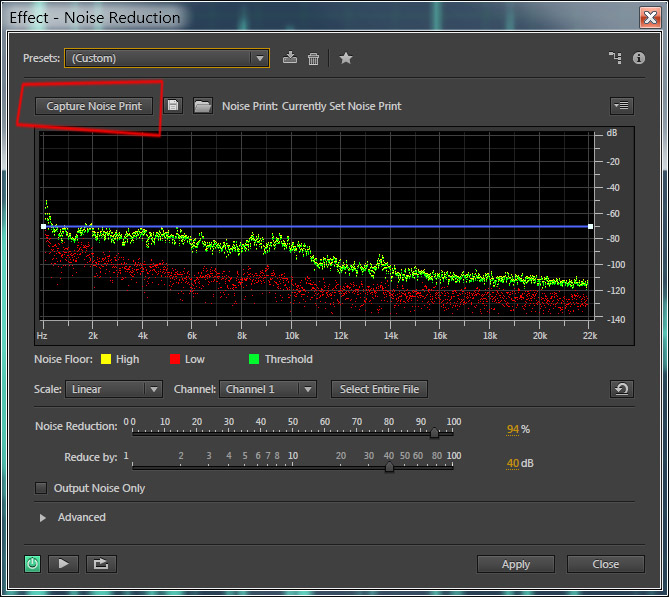
Здесь, нужно будет нажать на кнопку Capture Noise Print и в окне ниже появится график выделенного звукового сэмпла шума. Если данная кнопка не активна, то это означает, что вы выбрали слишком маленький кусочек шума, нужно закрыть диалоговое окно, выделить заново шум и вызвать эффект Noise Reduction. Смысл данного действия заключается в том, что программа запомнит частотную дорожку шума и попытается автоматически убрать все похожие частоты из трека. параметр Noise Reduction в 94% (можно и 100%, зависит от силы шума), остальное оставим по умолчанию и нажмем клавишу Applay .
Теперь обратите внимание, как будет выглядеть кусочек выделенного шума после применения эффекта. Звуковая волна стала практически прямой.
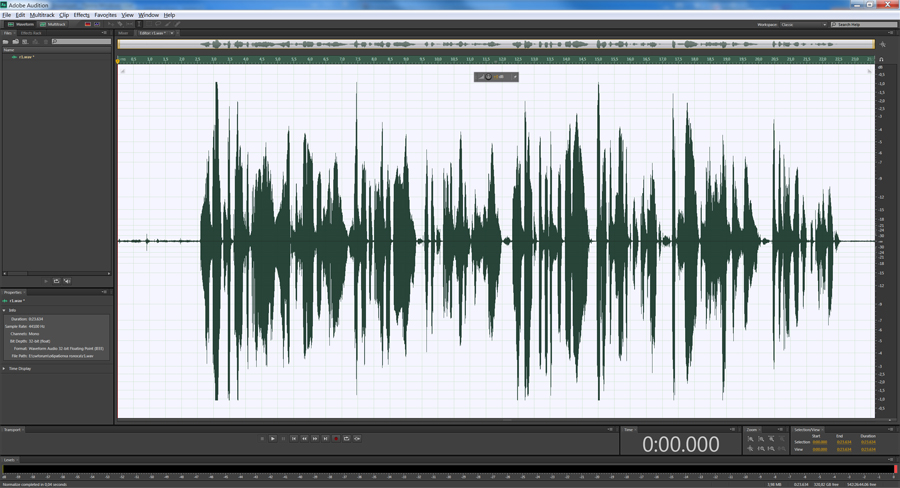
Теперь нужно избавиться от шумов во всем треке, для этого, выделим трек, нажав ctrl+A, вызовем тот же эффект и просто нажмем на кнопку Applay , образец шума будет использоваться старый, поэтому никаких настроек делать не надо. Трек будет выглядеть так:
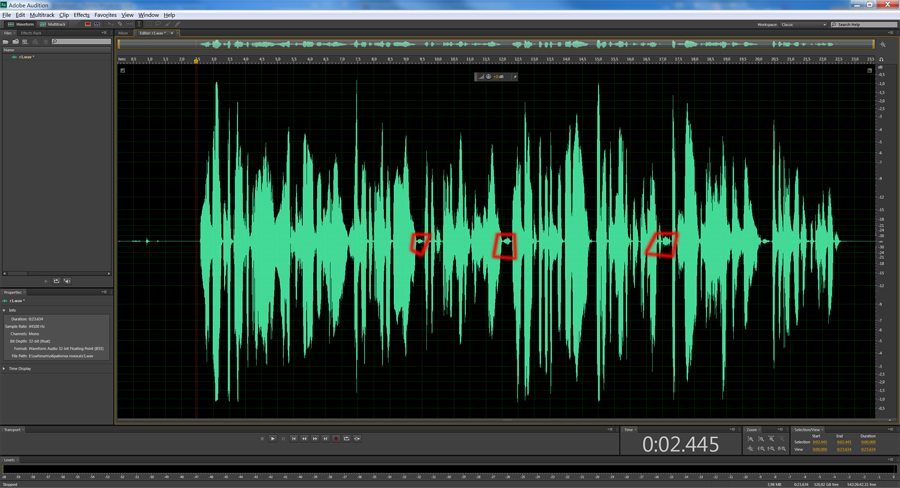
Обратите внимание, на выделенные красным цветом участки — это ненужные нам участки, на которые не подействовало шумоподавление, так как это запись дыхания. Избавимся от них вручную. Для этого выделим каждый из этих кусочков, щелкнем правой клавишей мыши и выберем пункт Silence .

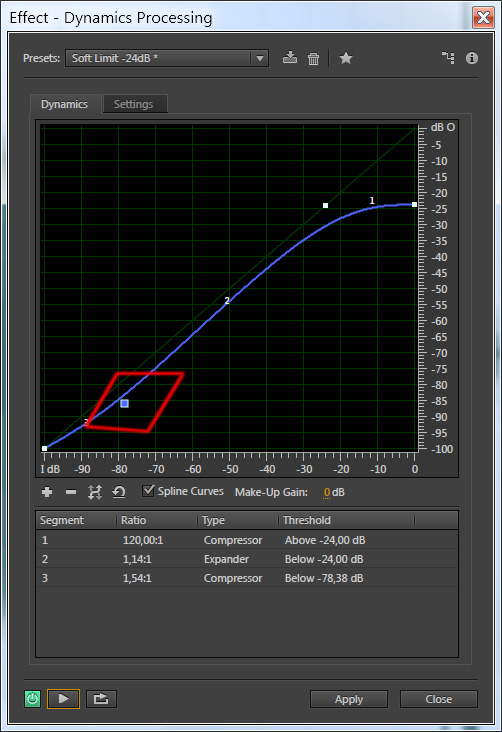
Я выбрала настройку Soft Limit -24dB и поэксперементировала с кривой — красным цветом выделена точка, которую я сдвинула. Вообще нужно всегда слушать к каким изменениям приводят ваши действия и выбирать то, что подходит по вашему слуху — универсальных настроек тут нет. А прослушать результат, вы всегда можете, не выходя из диалогового окна, нажав на клавишу Play в левом нижнем углу.

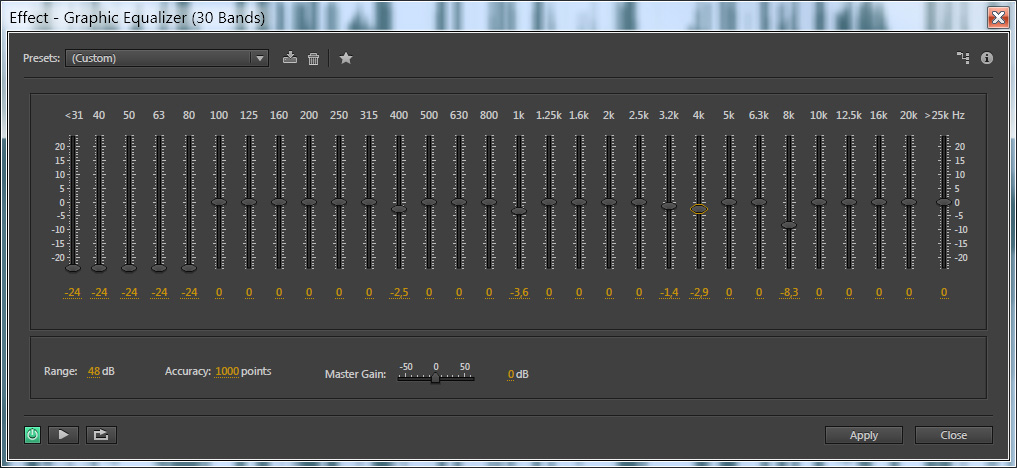
Голос после обработки
Теперь в принципе можно уже прослушать результат:
На этом я решила не останавливаться, поэтому:
6 шаг. Реверберация. Это эффект, который создаётся, когда какой либо звук звучит в замкнутом пространстве, в результате чего отражения от поверхностей стен вызывают большое количество эхо, затем звук медленно затухает по причине поглощения звуковых волн стенами и воздухом. Выберем пункт Effects — Reverb — Surround Reverd. Выставим значения так, чтобы было достигнуто желаемое звучание, не забываем прослушивать наши изменения. А у меня они такие:

В результате получилось следующее:
Надеюсь, моя статья оказалась для вас полезной. И не судите строго, так как все, что я сейчас показала я раскопала сама на просторах интернета без помощи профессионалов. Если вы считаете, что обладаете куда большими знаниями по качественной обработке голоса, то напишите о своем опыте в комментариях к данному посту. Будет очень интересно. Всего доброго!
по e-mail или социальных сетях
и мы обязательно опубликуем для вас еще больше полезной и интересной информации!
Этим постом мы хотели бы начать цикл статей, посвященных задаче изменения голоса. В зарубежной литературе данную задачу часто именуют термином voice morphing, в отечественной литературе данная задача ещё не получила достаточного освещения как в научных, так и в инженерных кругах. Тема является достаточно обширной и во многом творческой. В результате работы в данном направлении у нас накопился определенный опыт, который мы планируем систематизировать и изложить, а также передать основную суть некоторых алгоритмов.
Введение
Речевой тракт человека является едва ли не наиболее совершенным и гибким в сравнении со всеми известными животными и по разнообразию производимых звуков оставляет позади большинство музыкальных инструментов. Основная сложность в анализе и изменении голосового сигнала кроется именно в данном разнообразии и вытекающей большой неопределенности, связанной с вычленением и обработкой элементарных звуковых единиц. Не существует алгоритмов, хорошо подходящих для обработки всех звуков речи. К тому же, один и тот же элементарный звук человек может произносить по-разному в зависимости от своего эмоционального, физического состояния, от места звука в слове, etc. Индивидуальные особенности произношения, культурный и языковой фактор, медицинские патологии — все это также оказывает влияние на произносимый звук.
Звукообразование, общие сведения
Для понимания специфики обработки голосового сигнала, рассмотрим более подробно вопрос звукового состава речи и каким образом данные звуки образуются. Процесс звукообразования принято описывать с помощью двух основных понятий: фонация и артикуляция, опишем их по порядку.

Верхний график отражает значение U(t) во времени на выходе голосовой щели. Нижний график показывает первую производную U(t) по времени — суть изменение давления на выходе голосовой щели. Это периодическое изменение давления уже является звуком само по-себе. Данный звук состоит из шумовой и гармонической составляющих. Шумовая составляющая образуется турбулентностью из-за резкого увеличения U(t) и неполного смыкания голосовой щели (модель на картинке выше не учитывает шумовую составляющую). Гармоническая составляющая может быть представлена гармоническим рядом, где частоты всех вторичных гармоник (которые ещё называют обертонами) кратны частоте первой самой низкой гармоники, называемой частотой основного тона. (см. рисунок ниже).
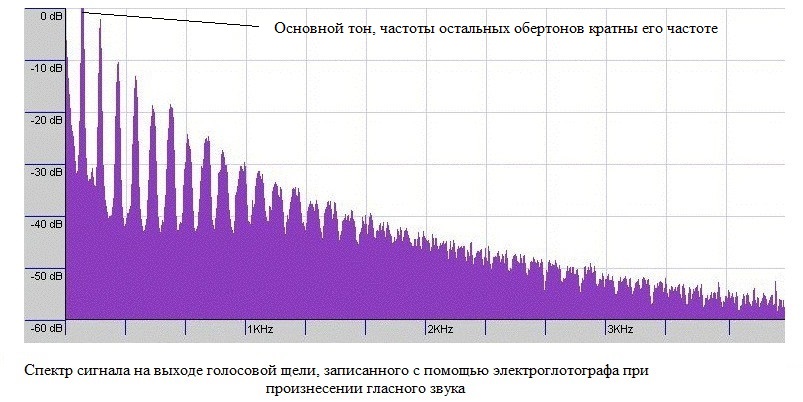
Физику образования данных гармоник в двух словах объяснить не получится, для этого лучше написать отдельную статью. Главное пока запомнить, что из гортани при работе связок уже может выходить вполне гармонический звук. Численное значение частоты основного тона равно частоте сокращения голосовых связок и является функцией от их длины, плотности и натяжения.
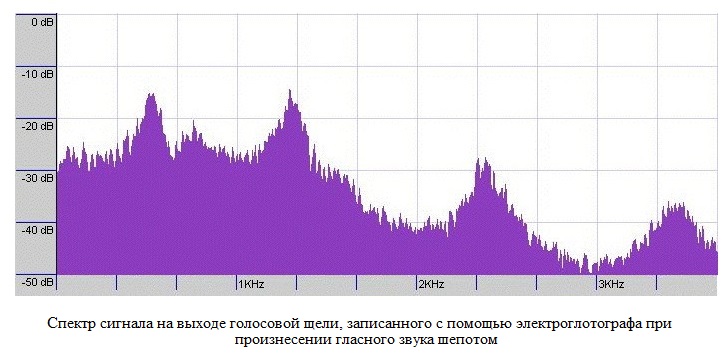

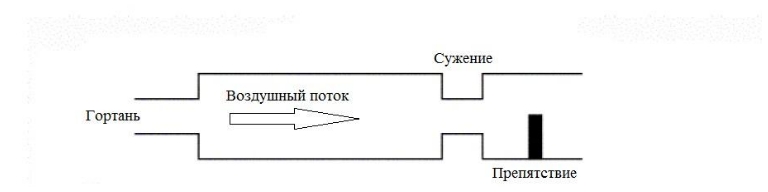
Артикуляция заключает в себе процесс изменения состояния всех элементов речевого тракта при звукопроизнесении. Фонация является частью артикуляции. Речевой тракт можно упрощенно представить совокупностью камер и трубок (см. рисунок справа), через которые проходит сигнал возбуждения. Сужения и расширение смычек голосового тракта, лежащих выше гортани, дополнительно влияют на скорость прохождения воздушного потока, формируют дополнительные (помимо голосовой щели) зоны турбулентности. Вместе с тем полости речевого тракта аналогичны акустическим резонаторам при прохождении через которые усиливаются одни и ослабляются другие частоты звука. Мышцы речевого тракта позволяют человеку контролировать геометрию камер речевого тракта, создавать препятствия на пути воздушного потока (язык, зубы, губы).
В грубом приближении можно резюмировать вышесказанное, как:
артикуляция = фонация + работа мышц речевого тракта,
где фонация может быть вокализованной или не вокализованной, а сокращение каждой отдельной мышцы — некоторая функция от времени.
В процессе обучения разговорной речи человек учится координировать работу органов артикуляции для получения определенных звуков. Из-за индивидуальных анатомических особенностей один и тот же звук у всех людей звучит немного по-разному, и это один из важных факторов, по которым мы отличаем голоса людей. При согласованной работе голосовых связок и остальных мышц речевого тракта, возможно образование гласных, согласных, смешанных и переходных звуков. Далее предлагается кратко рассмотреть эти группы, в общих чертах описать их артикуляцию и основные признаки.
Простейшая классификация звуков речи
Теперь перейдем к согласным звукам. Их количество значительно превышает количество гласных звуков и по своему звучанию они могут быть разбиты на подклассы. Как это часто бывает в реальной жизни, многие феномены имеют признаки многих классов и однозначная классификация весьма затруднительна. Согласные звуки в данном случае не являются исключением. Их разбиение на классы зависит от рассматриваемого языка и применяемой фонетической теории. Мы рассмотрим наиболее общую классификацию, состояюшую из трех основных групп:
— фрикативные согласные
— смычные согласные
— сонорные согласные
Генерируемый шумовой сигнал, как и в случае с гласными звуками, проходит через некоторое количество акустических фильтров (камеры речевого тракта), которые придают этому шуму некоторую характерную спектральную форму и звучание.

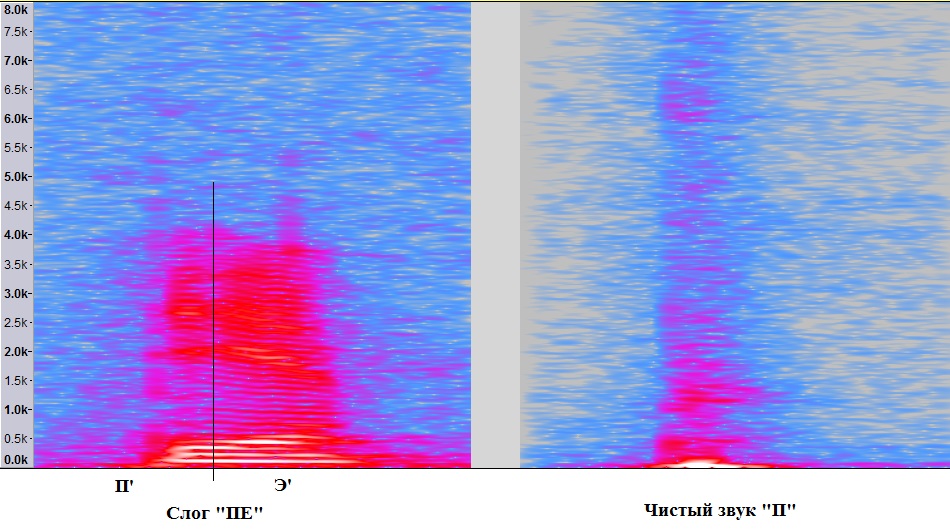
Следует обратить внимание, что все три попытки произношения звука значительно отличаются друг от друга во временной области. При этом на слух их отличить весьма тяжело.
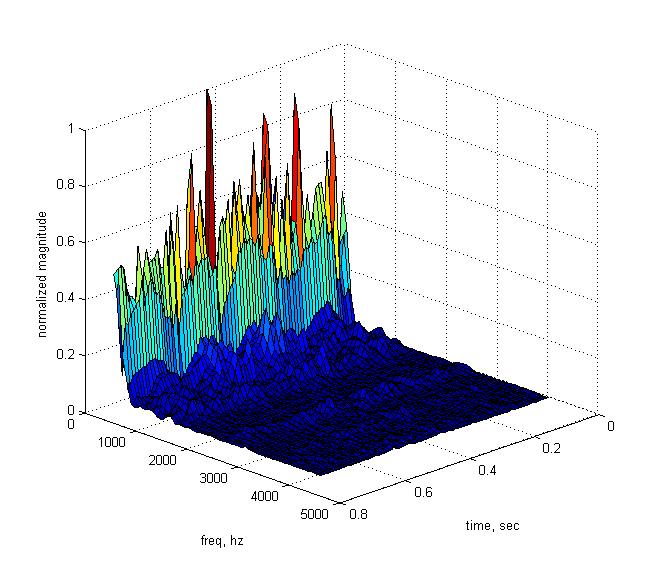
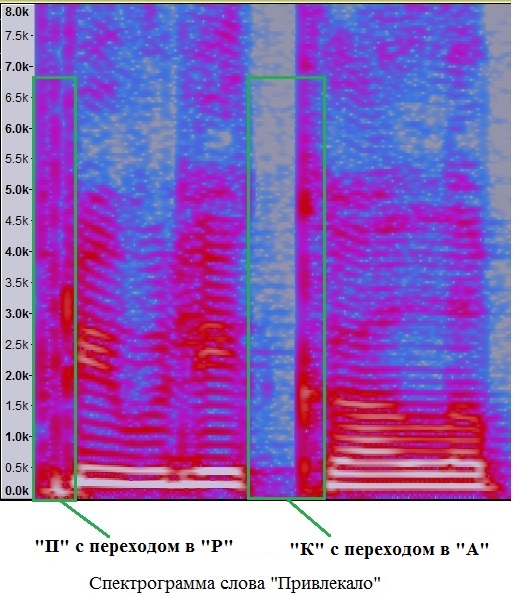
Пример спектрограммы слова с несколькими смычными звуками изображен ниже.
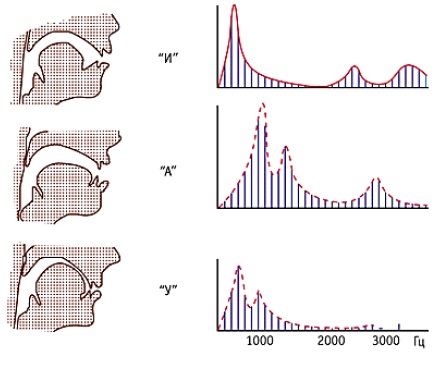
2. Гласные звуки несут в себе большее количество энергии, нежели согласные, основная её часть (1-я и 2-я форманты) лежат в диапазоне от 400 до 3000 Гц. Согласные звуки имеют значительно меньшую энергию. У большой части согласных звуков значительная часть этой энергии сосредоточена в области 2-10 КГц. Один из примеров показан ниже:
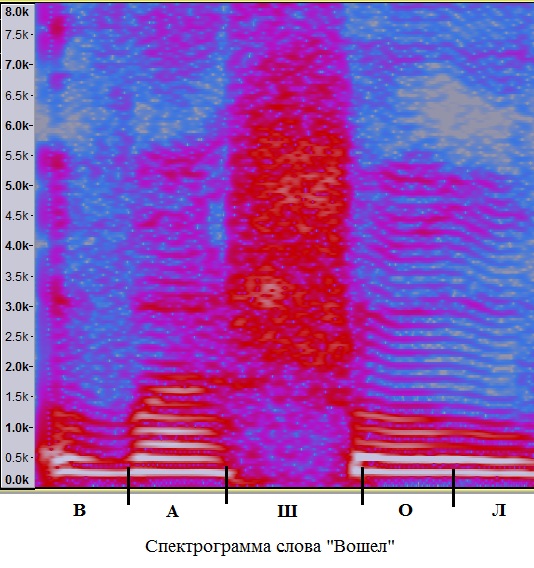
3. Гласные звуки имеют в среднем большую продолжительность, нежели согласные (100-300 мсек против 30-100 мсек, хотя конкретные точные цифры сильно зависят от языка и человека)
Речевой сигнал при слитной речи может условно считаться стационарным на отрезках от 5 до 100 миллисекунд в зависимости от особенностей диктора и произносимого звука. На более длительных интервалах анализа возрастает вероятность существенного изменения свойств сигнала, что может привести к несостоятельности оценок его усредненных параметров. Как и в любой другой области обработки сигналов, большие проблемы могут создать шумовые помехи, особенно те из них, которые имеют гармоническую природу и/или некоторые подобия формант — частотные области со сравнительно большой энергией.

Ведущий вокал, конечно же, является основным элементом большинства поп-музыки. Это делает его ключевой частью всего микса. Чистая запись голоса должна производиться с помощью высококачественного студийного (конденсаторного) микрофона в подходящем месте. Это неплохая отправная точка, но даже безупречные вокальные аудио записи могут совершенствоваться, пройдя соответствующую обработку. Часто это будет незаметно, но, как и во многих других аспектах микширования, дьявол кроется в деталях. Вот несколько практических советов по использованию VST эффектов для улучшения вокальной партии.
Питч: Корректируем высоту тона
Предполагается, что опытным вокалистам не потребуется корректировать высоту звука. Здесь продюсер на слух решает, что качество может быть улучшено. Профессиональные плагины коррекции питча (AutoTune, Melodyne и другие) могут автоматически выровнять фальшивую голосовую дорожку. Это действительно полезно, но надо знать о нескольких вещах.
Эквализация
Конечно, в контексте музыкальной композиции может потребоваться небольшой тонкий эквалайзер. В зависимости от используемого микрофона какой-то подъем в диапазоне 5–10 000 привнесёт незначительного присутствия. Это позволит вокалу немного преобладать над остальными дорожками. Пары дБ может быть достаточно, тем более что многие высококачественные студийные микрофоны уже содержат этот вид тонкого усиления присутствия.

Особым испытанием для эквалайзера окажется вокальная дорожка, записанная вживую, посредством сценического микрофона, такого как SM58 / 57. Получаем комбинацию менее воздушных верхних частот динамического сценического микрофона и усиления НЧ. Это результат эффекта близости (когда направленный микрофон находится близко ко рту певца). Здесь может потребоваться небольшая поправка эквалайзером. Широкий провал на несколько дБ в низких частотах примерно на 200 Гц помогает убрать излишне басовый тон. Рекомендуется поднять ползунки в диапазоне 10K+, что добавит немного приятной атмосферы. Не стоит ожидать, что это приведет к идеальным ВЧ и прозрачности, подобно студийным конденсаторным микрофонам.
Компрессия
Конкретные настройки компрессора сильно зависят от его типа и внутреннего алгоритма, который он использует для определения уровня и применения изменения усиления. Многие микшировщики порекомендовали бы оптический компрессор для вокала, такой как знаменитый Teletronix LA-2A. Можно также выбрать что-то среди программных эмуляций (VST плагинов), которые имеют несколько элементов управления для упрощения использования. Большинство таких эффектов могут предоставить множество желаемого сжатия / выравнивания. Они подойдут для превосходного общего контроля уровня в миксе, не делая вокал действительно сжатым.

Время и пространство
Конечно, для вокала обычно используются эффекты, основанные на времени. Самыми популярными из них являются реверберация и задержка. Все слышали, как пение в ванной делает голос полнее и эпичнее благодаря атмосфере помещения и его отражающим поверхностям. В то время как в некоторых музыкальных жанрах требуется относительно сухой фронтальный ведущий вокал, в большинстве случаев небольшая реверберация или окружающая среда добавляют голосу приятную глубину. Однако чрезмерное его использование может отодвинуть вокал на задний план микса, поэтому очень важно грамотно сбалансировать звучание. Изредка добавление небольшой задержки перед началом реверберации может предотвратить ненужное искажение голоса. Это позволяет использовать больше реверберации, не делая вокальный звук очень отдалённым. Такой параметр можно найти в некоторых продвинутых ревербераторах типа Giant Verb (обычно обозначается как Pre-Delay).
Современные VST плагины реверберации предоставляют множество типов этого эффекта. Для более тонкой атмосферы хорошим выбором станет пресет небольшой комнаты. На определённых вокалах будет уместно применение имитации старого механического устройства с подвешенными металлическими пластинами (Plate). Это сделает ваши голосовые аудио записи красивее и ярче.

Удвоение
Очень короткие задержки (около 15-20 миллисекунд) можно использовать для имитации двух или более вокалистов, поющих вместе одну и ту же партию. Вокальная дорожка дублируется, на копию накладывается Delay-эффект, и оба смешиваются вместе. Без банального эха сдвоенная вокальная партия часто имеет более полную и богатую тональность. Такое удвоение принято называть ADT (Artificial Double-Tracking). В аналоговую эпоху это первоначально было сделано с помощью дополнительного магнитофона, проигрывающего задержанный (дублированный) сигнал. Некоторые современные плагины имитируют тёплый, насыщенный характер удвоения на магнитной ленте. Иногда минимальное тонкое смещение высоты тона сочетается с дублированием, когда копии со смещенным питчем панорамируются в стороны для получения чуть более обширного вокального образа.

Xtra FX
Хотя при записи вокала традиционно избегают искажения, можно прибавить небольшое преднамеренное ухудшение, чтобы придать вокалу более агрессивный тембр. Это может быть имитация насыщенности ленты или даже Robovoice, если использовать плагины искажающих гитарных усилителей. Чтобы сохранить разборчивость, необходимо смешивать чистый вокал с небольшим количеством искаженного, обработанного голоса. Это обеспечивает максимальное наложение без ущерба для основного вокального звука.
Вершина айсберга
Конечно, это был лишь базовый этап некоторых стандартных техник настройки и улучшения вокальных треков. Отдельно выбранные эффекты и то, как они работают в конкретном миксе, было бы подходящей темой для более глубокого обсуждения. Надеюсь, этот беглый взгляд укажет начинающим битмейкерам и аранжировщикам интересные направления для творчества.

Читайте также: