Как сделать кластер kubernetes
Сегодняшний эксперт — Даниэль Поленчик ( Daniele Polencic ). Даниэль работает инструктором и разработчиком ПО в Learnk8s .
Если вы хотите получить ответ на свой вопрос в следующем посте, свяжитесь с нами по электронной почте или в Твиттере: @learnk8s .
Пропустили предыдущие посты? Ищите их здесь .
Как соединить кластеры Kubernetes в разных дата-центрах?
Кратко: скоро выходит Kubefed v2 , а еще советую почитать о Shipper и проекте multi-cluster-scheduler .
Довольно часто инфраструктура реплицируется и распределяется по разным регионам, особенно в контролируемых средах.
Если один регион недоступен, трафик перенаправляется в другой, чтобы избежать перебоев.
С Kubernetes можно использовать схожую стратегию и распределять рабочие нагрузки по разным регионам.
У вас может быть один или несколько кластеров на команду, регион, среду или на комбинацию этих элементов.
Ваши кластеры могут размещаться в различных облаках и в локальной среде.
Но как спланировать инфраструктуру для такого географического разброса?
Нужно создать один большой кластер на несколько облачных сред по единой сети?
Или завести много маленьких кластеров и найти способ контролировать и синхронизировать их?
Один руководящий кластер
Создать один кластер по единой сети не так-то просто.
Представьте, у вас авария, потеряна связность между сегментами кластера.
Если у вас один мастер-сервер, половина ресурсов не смогут получать новые команды, потому что им не удастся связаться с мастером.
И при этим у вас старые таблицы маршрутизации ( kube-proxy не может загрузить новые) и никаких дополнительных pod’ов (kubelet не может запрашивать обновления).
Что еще хуже, если Kubernetes не видит узел, он помечает его как потерянный и распределяет отсутствующие pod’ы по существующим узлам.
В итоге pod’ов у вас в два раза больше.
Если вы сделаете по одному мастер-серверу на каждый регион, будут проблемы с алгоритмом достижения консенсуса в базе данных etcd. (прим. ред. — На самом деле база данных etcd не обязательно должна находится на мастер-серверах. Ее можно запустить на отдельной группе серверов в одном регионе. Правда, получив при этом точку отказа кластера. Зато быстро.)
etcd использует алгоритм raft , чтобы согласовать значение, прежде чем записать его на диск.
То есть большинство экземпляров должны достичь консенсуса, прежде чем состояние можно будет записать в etcd.
Если задержка между экземплярами etcd резко вырастает, как в случае с тремя экземплярами etcd в разных регионах, требуется много времени, чтобы согласовать значение и записать его на диск.
Это отражается и на контроллерах Kubernetes.
Менеджеру контроллеров нужно больше времени, чтобы узнать об изменении и записать ответ в базу данных.
А раз контроллер не один, а несколько, получается цепная реакция, и весь кластер начинает работать очень медленно.
Сейчас не существует хороших примеров большой сети для одного кластера.
В основном, сообщество разработчиков и группа SIG-cluster пытаются понять, как оркестрировать кластеры так же, как Kubernetes оркестрирует контейнеры.
Вариант 1: федерация кластеров с kubefed
Впервые управлять коллекцией кластеров как единым объектом пробовали с помощью инструмента kube federation.
Начало было хорошим, но в итоге kube federation так и не стал популярным, потому что поддерживал не все ресурсы.
Он поддерживал объединенные поставки и сервисы, но, к примеру, не StatefulSets.
А еще конфигурация федерации передавалась в виде аннотаций и не отличалась гибкостью.
Представьте себе, как можно описать разделение реплик для каждого кластера в федерации с помощью одних аннотаций.
Получился полный беспорядок.
SIG-cluster проделали большую работу после kubefed v1 и решили подойти к проблеме с другой стороны.
Вместо аннотаций они решили выпустить контроллер, который устанавливается на кластерах. Его можно настраивать с помощью пользовательских определений ресурсов (Custom Resource Definition, CRD).
Для каждого ресурса, который будет входить в федерацию, у вас есть пользовательское определение CRD из трех разделов:
- стандартное определение ресурса, например деплой;
- раздел placement , где вы определяете, как ресурс будет распределяться в федерации;
- раздел override , где для конкретного ресурса можно переопределить вес и параметры из placement.
Вот пример объединенной поставки с разделами placement и override.
Как видите, поставка распределена по двум кластерам: cluster1 и cluster2 .
Первый кластер поставляет три реплики, а у второго указано значение 5.
Если вам нужно больше контроля над количеством реплик, kubefed2 предоставляет новый объект ReplicaSchedulingPreference, где реплики можно распределять по весу:
Структура CRD и API еще не совсем готовы, и в официальном репозитории проекта ведется активная работа.
Следите за kubefed2, но помните, что для рабочей среды он пока не годится.
Shipper чем-то похож на kubefed2.
Оба инструмента позволяют настраивать стратегию развертывания на нескольких кластерах (какие кластеры используются и сколько у них реплик).
Но задача Shipper — снизить риск ошибок при поставке.
В Shipper можно определить ряд шагов, которые описывают разделение реплик между предыдущим и текущим деплоем и объем входящего трафика.
Когда вы отправляете ресурс в кластер, контроллер Shipper пошагово развертывает это изменение по всем объединенным кластерам.
А еще Shipper очень ограничен.
Например, он принимает Helm-чарты как входные данные и не поддерживает vanilla ресурсы.
В общих чертах, Shipper работает следующим образом.
Вместо стандартной поставки нужно создать ресурс приложения, включающий Helm-чарт:
Shipper неплохой вариант для управления несколькими кластерами, но его тесная связь с Helm только мешает.
А вдруг мы все перейдем с Helm на kustomize или kapitan ?
Узнайте больше о Shipper и его философии в этом официальном пресс-релизе .
Kubefed v2 и Shipper работают с федерацией кластеров, предоставляя кластерам новые ресурсы через пользовательское определение ресурсов.
Но вдруг вы не хотите переписывать все поставки, StatefulSets, DaemonSets и т. д. для объединения?
Как включить существующий кластер в федерацию, не меняя YAML?
multi-cluster-scheduler — это проект Admirality , который занимается рабочими нагрузками планирования в кластерах.
Но вместо того, чтобы придумывать новый способ взаимодействия с кластером и оборачивать ресурсы в пользовательские определения, multi-cluster-scheduler внедряется в стандартный жизненный цикл Kubernetes и перехватывает все вызовы, которые создают поды.
Каждый создаваемый под сразу заменяется на пустышку.
multi-cluster-scheduler использует веб-hooks для модификации доступа , чтобы перехватить вызов и создать бездействующий pod-пустышку.
Исходный pod проходит через еще один цикл планирования, где после опроса всей федерации принимается решение о размещении.
Наконец, pod поставляется в целевой кластер.
В итоге у вас лишний pod, который ничего не делает, просто занимает место.
Преимущество в том, что вам не пришлось писать новые ресурсы для объединения поставок.
Каждый ресурс, создающий pod, автоматически готов для объединения.
Это интересно, ведь у вас вдруг появляются поставки, распределенные по нескольким регионам, а вы и не заметили. Впрочем, это довольно рискованно, ведь здесь все держится на магии.
Но если Shipper старается, в основном, смягчить последствия поставок, multi-cluster-scheduler выполняет более общие задачи и, возможно, лучше подходит для пакетных заданий.
У него нет продвинутого механизма постепенных поставок.
Больше о multi-cluster-scheduler можно узнать на странице официального репозитория .
Если хотите прочитать о multi-cluster-scheduler в действии, у Admiralty есть интересный случай применения с Argo — рабочими процессами, событиями, CI и CD Kubernetes.
Другие инструменты и решения
Соединение нескольких кластеров и управление ими — сложная задача, универсального решения не существует.
Если вы хотите подробнее изучить эту тему, вот вам несколько ресурсов:
- Submariner от Rancher — инструмент, соединяющий оверлей-сети разных кластеров Kubernetes.
- Розничная сеть Target использует Unimatrix в сочетании Spinnaker, чтобы оркестировать деплой на нескольких кластерах .
- Попробуйте использовать IPV6 и единую сеть в нескольких регионах .
- Можно использовать service mesh, например Istio для соединения нескольких кластеров .
- Cilium, плагин интерфейса сети контейнеров, предлагает функцию cluster mesh , которая позволяет сочетать несколько кластеров
Вот и все на сегодня
Спасибо, что дочитали до конца!
Если вы знаете, как эффективнее соединить несколько кластеров, расскажите нам .
Kubernetes стал первым законченным проектом для CNCF и одним из самых быстрорастущих проектов с открытым исходным кодом в истории. К настоящему моменту Kubernetes насчитывает более 2300 участников и широко используется как крупными, так и мелкими компаниями, а также половиной списка Fortune 100.
Основы Kubernetes—Основные термины
Для начала познакомимся с несколькими основными терминами, связанными с Kubernetes. Более подробный список представлен на странице глоссария стандартных терминов по Kubernetes. Можно также воспользоваться Памяткой по Kubernetes, содержащей список популярных флагов и команд kubectl.
Кластер
Набор машин, по отдельности называемых узлами, которые используются для запуска контейнерных приложений, управляемых Kubernetes.
Виртуальная или физическая машина. Кластер состоит из главного узла и нескольких рабочих узлов.
Облачный контейнер
Образ, содержащий программное обеспечение и его зависимости.
Модуль
Один контейнер или набор контейнеров, работающих в кластере Kubernetes.
Развертывание
Объект, управляющий реплицированными приложениями, которые представлены модулями. Модули развертываются на узлах кластера.
Набор реплик
Обеспечивает одновременное выполнение определенного количества реплик модулей.
Сервисы
Описывает процесс получения доступа к приложениям, представленным набором модулей. Сервисы обычно описывают порты и балансировщики нагрузки и могут использоваться для управления внутренним и внешним доступом к кластеру.
Что такое KubeCon?
KubeCon — это ежегодная конференция разработчиков и пользователей Kubernetes. Со времени первой конференции KubeCon, прошедшей в 2015 году и собравшей 500 участников, KubeCon стала важным событием для cloud native сообщества. В 2019 году команда KubeCon в Сан-Диего, штат Калифорния, собрала 12 000 разработчиков и инженеров по обеспечению надежности сайтов для проведения мероприятия, посвященного созданию экосистемы с открытым исходным кодом на базе платформы облачной оркестрации Kubernetes.
Что такое контейнеры Kubernetes?
Сравнение Kubernetes и Docker
Хотя контейнеры Linux существуют с 2008 года, они стали известны только благодаря появлению контейнеров Docker в 2013 году. Точно так же взрыв интереса к развертыванию контейнерных приложений — приложений, содержащих все необходимое для работы, — в конечном итоге создал новую проблему: управление тысячами контейнеров. Kubernetes автоматически организует жизненный цикл контейнера, распределяя контейнеры по инфраструктуре хостинга. Kubernetes увеличивает или уменьшает объем ресурсов в зависимости от потребности. Платформа подготавливает, планирует, управляет и контролирует работоспособность контейнеров.
Из каких компонентов состоит Kubernetes?
Основными компонентами Kubernetes являются кластеры, узлы и плоскость управления. Кластеры содержат узлы. Каждый узел включает в себя как минимум одну рабочую машину. На узлах размещаются модули, содержащие элементы развернутого приложения. Плоскость управления управляет узлами и модулями в кластере, часто на большом количестве компьютеров, для обеспечения высокой доступности.

Плоскость управления включает следующие компоненты.
Компоненты узла включают следующее.
- kubelet: агент, проверяющий, что контейнеры работают в модуле.
- Сетевой прокси Kubernetes: поддерживает сетевые правила.
- Docker, containerd или другой тип среды выполнения контейнеров
Какие преимущества дает Kubernetes?
С контейнерами Вы можете быть уверены, что Ваши приложения укомплектованы всем, что им нужно для работы. Но по мере добавления контейнеров, которые часто содержат микросервисы, Вы можете автоматически управлять ими и распространять их с помощью Kubernetes.
Возможности, которые Kubernetes дает компаниям:
| Автоматическое масштабирование. | Увеличение или уменьшение развертывания в зависимости от потребности. |
| Поиск сервисов | Поиск контейнерных сервисов по DNS или IP-адресу. |
| Балансировка нагрузки | Стабилизация развертывания за счет распределения сетевого трафика. |
| Управление хранилищем | Выбор локального или облачного хранилища. |
| Контроль версий | Выберите типы контейнеров, которые Вы хотите запустить, и те, которые нужно заменить, используя новый образ или ресурсы контейнера. |
| Обеспечение безопасности | Безопасное обновление паролей, токенов OAuth и ключей SSH, связанных с определенными образами контейнеров. |
Какие проблемы возникают при использовании Kubernetes?
Несмотря на то что платформа Kubernetes легко компонуется и может поддерживать приложения любого типа, в ней сложно разобраться и ее непросто использовать. По словам некоторых членов CNCF, Kubernetes не всегда является правильным решением для конкретной нагрузки. Вот почему экосистема Kubernetes содержит ряд связанных cloud native инструментов, которые компании создали для решения конкретных проблем с нагрузками.
Kubernetes развертывает контейнеры, а не исходный код и не создает приложения. Для ведения журналов, промежуточного программного обеспечения, мониторинга, настройки, CI/CD и многих других производственных операций требуются дополнительные инструменты. Тем не менее платформа Kubernetes является расширяемой и доказала свою эффективность в самых разных сценариях использования — от реактивных самолетов до машинного обучения. Фактически поставщики облачных решений, включая Oracle, Google, Amazon Web Services и другие, используют собственную расширяемость Kubernetes для создания управляемых Kubernetes, которые представляют собой сервисы для снижения сложности и повышения продуктивности разработчиков.
Что такое управляемый Kubernetes?
Oracle Cloud Infrastructure Container Engine for Kubernetes — это удобный для разработчиков управляемый сервис, который можно использовать для развертывания контейнерных приложений в облаке. Используйте Container Engine for Kubernetes, если Ваша команда разработчиков хочет надежно создавать, развертывать cloud native приложения и управлять ими. Вы указываете вычислительные ресурсы, которые требуются Вашим приложениям, а Oracle Container Engine for Kubernetes предоставляет их в существующей арендованной облачной инфраструктуре Oracle.
Несмотря на то что Вам необязательно использовать управляемый сервис Kubernetes, решение Oracle Cloud Infrastructure Container Engine for Kubernetes — это простой способ запустить высокодоступные кластеры с контролем, безопасностью и предсказуемой производительностью Oracle Cloud Infrastructure. Container Engine for Kubernetes поддерживает как системы без виртуализации, так и виртуальные машины как узлы, и сертифицирован соответствующим образом организацией CNCF. Вы также получаете все обновления Kubernetes, и совместимость с экосистемой CNCF обеспечивается без каких-либо дополнительных действий с Вашей стороны.
Cloud Native и Kubernetes меняют подход AgroScout к поддержке разработчиков.
Создайте учетную запись бесплатно. Попробуйте бесплатно кластер Kubernetes с высочайшим уровнем безопасности.
Что вы получаете
1 бесплатный кластер Kubernetes
Включен 1 рабочий узел. Доступен в течение 30 дней.
Более 40 полностью бесплатных продуктов
Ваш бесплатный кластер легко интегрируется с IBM Cloud Container Registry и другими продуктами.
Кредит в размере USD 200
Кредит на 30 дней позволяет попробовать все возможности IBM Cloud.
Продукты IBM Cloud
Самые популярные продукты IBM Cloud для экосистемы Kubernetes
Бесплатный кластер на 30 дней с 1 рабочим узлом
Развертывание безопасных, высокодоступных приложений стандартными средствами Kubernetes.
5 ГБ в месяц для передачи данных
Управляйте образами контейнеров Docker с помощью полностью управляемого частного реестра.
500 заданий процесса поставки
Поддержка передовых методов DevOps с использованием Git, систем отслеживания неполадок, конвейеров CI/CD и Eclipse Orion Web IDE в облаке.
25 ГБ в месяц
Гибкое и экономичное хранилище для неструктурированных данных.
1 ГБ в хранилище данных
Масштабируемая документо-ориентированная база данных JSON для мобильных, бессерверных и веб-приложений, а также приложений IoT.
До 1000 временных рядов на 30 дней
Оперативный контроль производительности и состояния приложений, услуг и инфраструктуры.
1 пользователь
Объединение журналов приложений и серверов с возможностью поиска на основе единой платформы.
10000 вызовов API в месяц
Добавьте к своему приложению интерфейс естественного языка, чтобы автоматизировать взаимодействие с пользователями.
Продукты бесплатного уровня с неограниченным сроком действия
25 ГБ в месяц
Гибкое и экономичное хранилище для неструктурированных данных.
20 единиц емкости-часов
Построение аналитических моделей и нейронных сетей, обученных на ваших данных, и их развертывание для использования в приложениях.
1 авторизованный пользователь
Технологии ИИ и машинного обучения, которые можно встроить в бизнес-процессы. Создание пользовательских моделей с использованием собственных данных.
100000 последних операций в облаке
Анализ данных о пользователях и их приложениях с помощью услуг IBM Cloud.
10000 вызовов API в месяц
Интерфейс обработки естественного языка для автоматизации взаимодействия с пользователями.
1000 событий ежемесячно
Аутентификация пользователей мобильных приложений и веб-приложений, а также защита API и серверных компонентов, выполняемых в IBM Cloud.
500 минут в месяц
Малое время отклика, расшифровка потоковых данных.
10000 символов в месяц
Преобразование текста в речь с естественным звучанием.
200 МБ в хранилище данных
Полностью управляемая облачная база данных SQL со сверхскоростным ядром Db2.
1 ГБ в хранилище данных
Масштабируемая документо-ориентированная база данных JSON для мобильных, бессерверных и веб-приложений, а также приложений IoT.
50 часов
Разработка и внедрение аналитических приложений с помощью Apache Spark и Apache Hadoop с открытым исходным кодом.
1 каталог
Обучение IBM Watson; классификация и безопасный обмен корпоративными данными.
500 заданий процесса поставки
Поддержка передовых методов DevOps с использованием Git, систем отслеживания неполадок, конвейеров CI/CD и Eclipse Orion Web IDE в облаке.
1000000 символов в месяц
Перевод текстов, документов и веб-сайтов на другой язык.
1000 документов в месяц
Когнитивная система поиска и анализа информации в приложениях.
5 ГБ в месяц для передачи данных
Управление образами контейнеров Docker с помощью полностью управляемого частного реестра.
1000 вызовов API в месяц
Извлечение ценной информации из данных о транзакциях и социальных сетей для выявления психологических характеристик.
2500 вызовов API в месяц
Распознавание языковых интонаций, в том числе эмоционального окраса, социальной составляющей и стилей изложения.
2 специализированные модели
Анализ изображений с целью определения окружения, объектов, лиц и другой информации.
1 специализированная модель
Анализ текста и извлечение метаданных из материалов: понятий, сущностей, эмоций, настроения и т. п.
Бесплатная пробная версия действует в течение 30 дней. По окончании указанного бесплатного периода начинает взиматься плата.
100 000 vCPU-секунд в месяц
Выполнение приложения, пакетного задания или контейнера на управляемой бессерверной платформе.
1 кластер на 30 дней
Развертывание безопасных, высокодоступных приложений стандартными средствами Kubernetes.
2 ГБ хранилища данных на 30 дней
Полностью управляемая база данных, размещенная в среде IBM Cloud Hyper Protect. В настоящее время поддерживает MongoDB 3.6.4.
5 млн выполнений в месяц
Выполнение функций в ответ на входящие события.
1000 сертификатов для каждого экземпляра
Управление SSL-сертификатами для приложений и услуг в IBM Cloud.
Неограниченный объем входящих данных
Помогает быстро и безопасно переносить данные из локального хранилища в ЦОД IBM Cloud.
30-дневная пробная версия
Повышенная надежность, производительность и безопасность интернет-приложений, веб-сайтов и служб.
1 vCPU на 30 дней
Создание и запуск виртуальных серверов на базе Linux в вычислительной среде с высоким уровнем конфиденциальности.
2 ГБ хранилища данных на 30 дней
Долгосрочное хранение данных PostgreSQL в полностью зашифрованной клиентской базе данных, работа с которой не требует специальных навыков.
20 ключей
Услуга помогает управлять ключами шифрования для защиты данных.
Избранные продукты с ограниченным сроком действия и количеством пользователей. Не применяется для сотрудников IBM.
Купите 1 месяц, получите 2 месяца бесплатно
Промокод: 2FREE2174
Действует до 2 февраля 2022 года
Оформите подписку на физический сервер IBM Cloud с процессором Intel® Xeon® E-2174G 2 поколения сроком на 1 месяц и получите два дополнительных месяца в подарок.
Купите 1 месяц, получите 2 месяца бесплатно
Промокод: 2FREE8260
Действует до 2 февраля 2022 года
Оформите подписку на физический сервер IBM Cloud с процессором Intel® Xeon® Scalable Platinum 8260 2 поколения сроком на 1 месяц и получите два дополнительных месяца в подарок.
Кредит USD 500
Промокод: VPC500
Действует до 31 декабря 2021 года
Кредит в размере USD 500 на 180 дней на IBM Cloud® Virtual Server для VPC, IBM Cloud Block Storage для VPC и IBM Cloud® Image Service для VPC
Кредит USD 500
Промокод: FREE500VM
Действует до 31 декабря 2021 года
Кредит в размере USD 500 на решения VMware от IBM сроком на 90 дней
Кредит в размере USD 3,120
Промокод: HPCRYPTO30
Действует до 31 декабря 2021 года
Кредит в размере USD 3,120 на продукты IBM Cloud Hyper Protect Crypto Services сроком на 30 дней
Кредит в размере USD 3,120
Промокод: HPCRYPTO30PLUS
Действует до 31 декабря 2021 года
Кредит в размере USD 3,120 на продукты IBM Cloud Hyper Protect Crypto Services сроком на 30 дней
Кредит в размере USD 600
Промокод: CLDNT_TXE_STD
Действует до 31 декабря 2021 года
Кредит на IBM Cloudant® на сумму USD 600 в течение 90 дней
Кредит в размере USD 600
Промокод: DBFREE601
Действует до 31 декабря 2021 года
Кредит в размере USD 600 сроком на 90 дней на базы данных IBM Cloud® Databases for PostgreSQL, IBM Cloud Databases for MongoDB, IBM Cloud® Databases for Elasticsearch и IBM Cloud® Databases for Redis.
Кредит в размере USD 1,500
Промокод: EDBFREE1500
Действует до 31 декабря 2021 года
Кредит в размере USD 1,500 на IBM Cloud Databases for EnterpriseDB сроком на 90 дней
Кредит в размере USD 1,500
Промокод: DSEFREE1500
Действует до 31 декабря 2021 года
Кредит в размере USD 1,500 на IBM Cloud Databases for DataStax сроком на 90 дней
Кредит в размере USD 1,500
Промокод: MONGOFREE1500
Действует до 31 декабря 2021 года
Кредит в размере USD 1,500 на IBM Cloud Databases for MongoDB Enterprise Plan на 90 дней
Кредит USD 500
Промокод: NETAPP500
Действует до 31 декабря 2021 года
Кредит в размере USD 500 на файловое хранилище в IBM Cloud на 90 дней
Кредит USD 500
Промокод: NETAPP500
Действует до 31 декабря 2021 года
Кредит в размере USD 500 на блочное хранилище в IBM Cloud на 90 дней
Часто задаваемые вопросы
Какая поддержка предоставляется для моей учетной записи?
Для вашей учетной записи доступен базовый уровень поддержки. Он рассчитан на непроизводственные среды или приложения, в которых не используются традиционные уровни серьезности и не оговаривается конкретное время отклика. Если вы захотите повысить уровень поддержки, вы можете перейти на Расширенный или Премиальный планы. Более подробную информацию можно получить в документе Базовый, Расширенный и Премиальный планы поддержки.
Как настроить уведомления о расходах?
Любой владелец или пользователь учетной записи с ролью редактора (или выше) для службы выставления счетов может включить уведомления о расходах. Уведомления о расходах можно включить для общего счета, среды выполнения Cloud Foundry, контейнеров и услуг, или же добавить отдельные услуги (включая услуги сторонних производителей).
Уведомления отправляются по достижении 80%, 90% и 100% от установленных лимитов по расходам. Лимиты можно корректировать по мере изменения потребностей. При желании можно выбрать в учетной записи до 10 пользователей для получения уведомлений об услуге.
В бесплатных учетных записях включение уведомлений о расходах не поддерживается, поскольку им доступны только бесплатные уровни услуг, не предполагающие никаких расходов. После перехода на учетную запись с оплатой по факту использования или оформления подписки можно установить лимиты расходов. Дополнительные сведения можно найти в разделе Типы учетных записей.
Как настроить уведомления:
Также можно включить уведомления о расходах для отдельных услуг:
Примечание: Уведомления о расходах на классические инфраструктурные услуги не рассылаются.

Дисклеймер: Данная статья не несёт в себе практических описаний того, как реализовать выкладку вашего приложения в Kubernetes. Какую конечную версию решения и какие инструменты будете использовать — решать только вам.
Контейнеризированные приложения продолжают захватывать мир. Та революция, которую начал Docker, будет приобретать всё большие масштабы. После Docker к нам в 2014 году, а если брать версию 1.0 — в 2015, пришёл Kubernetes, и, давайте скажем честно, он классный. Он позволяет решать кучу задач в автоматическом режиме, из-за которых вы, скорее всего, как OPS-инженер могли плохо спать по ночам. Kubernetes принёс нам новый уровень абстракций над контейнеризированными приложениями. И сейчас большинство компаний стремятся перетащить в него свою рабочую нагрузку и управлять через него своими приложениями. А там, где есть приложения, нам надо продумать, как мы будем их выкатывать. Об этом сегодня и поговорим.
Модели доставки кода в кластер
И вот тут я должен сделать первое и главное для нас уточняющее разъяснение. На мой взгляд, существует две модели доставки кода в кластер — условные Pull и Push. В модели Pull мы передаём новое желаемое состояние кластера путём применения манифестов через kubectl, Helm, Kustomize или любым другим методом. В модели Push реализован подход GitOps.
В кластере Kubernetes есть механизм, который следит за Git-репозиторием, и в случае изменения в нём кода, этот механизм приводит кластер в состояние, чётко описанное этим кодом. Почему это хорошо? Потому что у вас есть один источник правды — SST (Single Source of Truth). Допустим, ручное изменение количества ReplicaSet c двух до трёх не будет сохранено на долгое время, так как механизм согласования вернёт кластер в состояние, описанное в Git-репозитории.
Деплой манифестов. Модель Pull
Взглянем на изображение ниже.
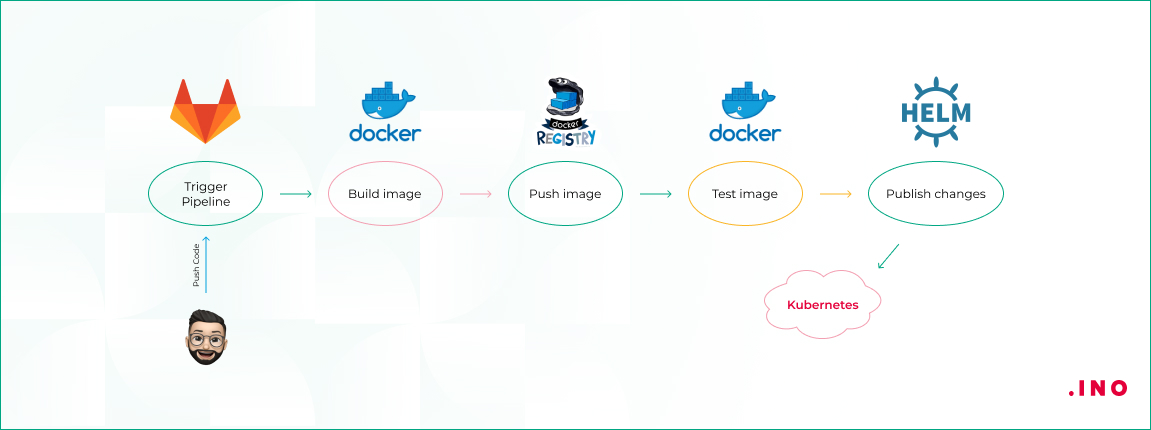
На скрине схематично показан процесс выката приложения
Разработчик пушит изменения в Git-репозиторий, в данном случае это GitLab, но может быть Bitbucket или GitHub, это неважно. В этом репозитории также хранится ваше описание Kubernetes, это могут быть Helm-чарты или просто манифесты YAML — решать вам в зависимости от ваших предпочтений. Вы можете хранить файлы описания в отдельном репозитории. Но тогда в случае, например, с GitLab, нужно будет воспользоваться хуками для активации выкладки с изменёнными параметрами после сборки образа.
Продолжим. Изменения в коде триггерят активацию пайплайна сборки. Как вы будете собирать изменения тоже неважно — Jenkins, GitLab CI/CD или любой другой механизм. Главное — понять концепцию. Активация пайплайна заставляет сборщик собрать новый образ приложения и опубликовать его в реестре контейнеров. Используйте теги или переменные окружения для версионирования образов.
Далее наш собранный образ проходит автоматические тесты. Затем мы разворачиваем наш релиз — в примере с помощью Helm — в наш кластер Kubernetes. Не забываем про встроенную возможность сделать rollback. В общем, так выглядит стандартная схема деплоя приложения в кластер. Обязательно продумайте, как у вас будет выполняться миграция, как эффективно убрать даунтайм приложения или то, как и куда будут попадать пользователи во время деплоя.
GitOps подход. Модель Push
Давайте взглянем на схему реализации push-модели.
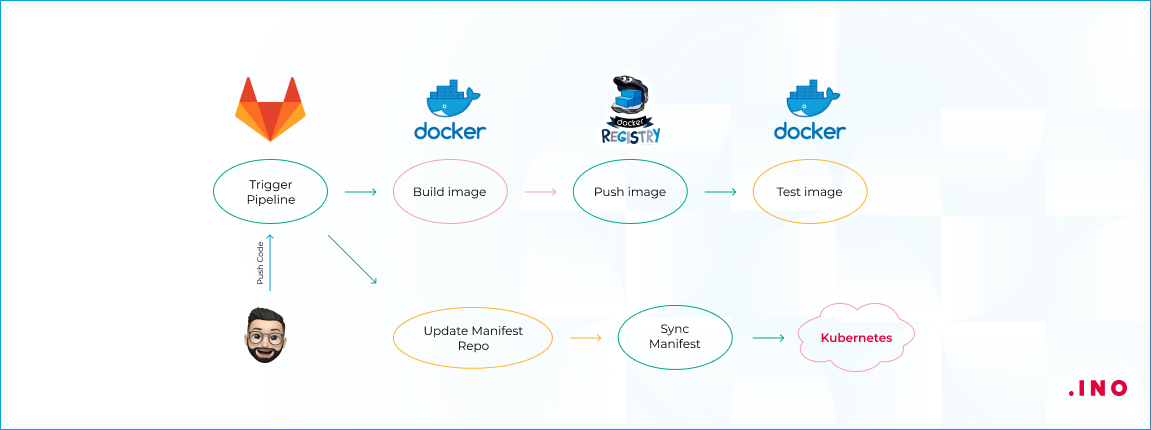
Данный подход предполагает использование двух репозиториев. В первом репозитории мы храним код нашего приложения. Там же мы храним Docker-файлы для сборки, но не храним Helm-чарты или описания желаемого состояния кластера в простых манифестах или с применением kustomize. Триггер сборки активирует пайплайн, который собирает и тестирует новый образ приложения, а также пушит его в registry.
Затем вносятся изменения в репозиторий с манифестами, которые описывают желаемое состояние кластера. Далее оператор синхронизации — в данном случае представлен Argo CD, однако вы можете использовать Flux2 — определяет, что текущее состояние не соответствует описанному состоянию в репозитории, и приводит кластер к этому состоянию. Оператор синхронизации является приложением, предварительно задеплоенным в кластер. Хранение манифестов в отдельном репозитории с их синхронизацией упрощает ваш CI-пайплайн, избавляя его от задач выката приложения.
Сегодня мы рассмотрели две основные модели CI/CD-доставки кода в кластер Kubernetes. Надеюсь, после этой статьи стало немного понятнее, как реализовать выкладку вашего приложения. По какой модели лучше работать — решать вам. Всё будет зависеть от тех задач, которые выполняет приложение, и от того, из каких компонентов оно состоит. Важно использовать Kubernetes с умом и не забывать, что мы используем инструменты для достижения цели, а не ставим цели, чтобы для них подходили конкретные инструменты.

Kubernetes (k8s) очень стремительно становится новым стандартом для деплоймента и менеджмента вашего кода в клауде. Вместе с тем, сколько фич предоставляет k8s, для новичка наступает высокий порог входа в новую технологии.
Документация по k8s достаточно обширна и довольно сложно пройти ее всю. Именно по этому эта статья служит неким обобщением для того, чтобы разобрать основные модули kubernetes.
Hardware
Nodes

Node - это самая маленькая единица 'computing hardware в k8s. Это представление одной машины в вашем кластере. В большинстве производственных систем нодой, корее всего, будет либо физическая машина в датацентре, либо виртуальная машина, размещенная на облачном провайдере, таком как Google Cloud Platform, Azure, AWS. Однако, вы можете сделать ноду практически из чего угодно (например Rasbery PI).
Если обсуждать про машину как "ноду", можем разбавить это слоем абстракции, мы можем представлять ее как некий набор CPU, RAM ресурсов которые можно использовать. Таким образом любая такая машина может заменить любую другую машину как k8s кластер.
Cluster

Хотя работа с отдельными нодами может быть полезной, это не путь kubernetes. В общем, вы должны думать о кластере в целом, а не беспокоиться о состоянии отдельных нодов.
В Kubernetes ноды объединяют свои ресурсы для формирования более мощной машины. Когда вы развертываете программы в кластере, он балансирует нагрузку по индивидуальным нодам для вас. Если какие-либо nodes добавляются или удаляются, кластер будет перемещаться по мере необходимости. Для программы или девелопера не должно быть важно, на каких машинах выполняется код в k8s. Можно сравнить такую систему с улием.
Persistent Volumes
Поскольку программы, работающие в вашем кластере, не гарантированно выполняются на определенной ноде, данные не могут быть сохранены в любом произвольном месте в файловой системе. Если программа пытается сохранить данные в файл, но затем перемещается на новую ноду, файл больше не будет там, где программа ожидает его. По этой причине традиционное локальное хранилище, связанное с каждой нодой, рассматривается как временный кэш для хранения программ, но нельзя ожидать, что любые данные, сохраненные локально, сохранятся.

Для постоянного хранения данных Kubernetes использует Persistent Volumes. Хотя ресурсы ЦП и ОЗУ всех нодов эффективно объединяются и управляются кластером, постоянного хранение файлов - нет. Вместо этого локальные или облачные диски могут быть подключены к кластеру как постоянный том (Persistent Volumes). Это можно рассматривать как подключение внешнего жесткого диска к кластеру. Persistent Volumes предоставляют файловую систему, которая может быть подключена к кластеру без привязки к какому-либо конкретному ноду.
Software
Контейнеры

Программы, работающие на Kubernetes, упаковуются в контейнеры. Контейнеры являются общепринятым стандартом, поэтому уже есть много готовых образов, которые можно развернуть в Kubernetes.
Контейнеризация позволяет вам создавать self-contained environments. Любая программа и все ее зависимости могут быть объединены в один файл и затем опубликованы в Интернете. Любой может загрузить контейнер и развернуть его в своей инфраструктуре с минимальными настройками. Создание контейнера может быть сделано и скриптом, позволяя строить CI/CD пайплайны.
Несколько программ могут быть развернуты в одном контейнере, но вы должны ограничить себя одним процессом на контейнер, если это вообще возможно. Лучше иметь много маленьких контейнеров, чем один большой. Если каждый контейнер имеет четкую направленность, обновления легче развертывать, а проблемы легче диагностировать.

В отличие от других систем, которые вы, возможно, использовали в прошлом, Kubernetes не запускает контейнеры напрямую; вместо этого он упаковывает один или несколько контейнеров в структуру более высокого уровня, называемую pod. Любые контейнеры в одном pod'e будут использовать одни и те же ресурсы и локальную сеть. Контейнеры могут легко связываться с другими контейнерами в том же pod'e, как если бы они находились на одной машине, сохраняя степень изоляции от других pod'ов.
Pod'ы используются как единица репликации в Kubernetes. Если ваше приложение становится слишком популярным, и один экземпляр модуля не может нести нагрузку, Kubernetes можно настроить для развертывания новых реплик вашего модуля в кластере по мере необходимости. Даже если не под большой нагрузкой, в продакшинев любое время можно запустить несколько копий модуля в любое время, чтобы обеспечить балансировку нагрузки и устойчивость к сбоям.
Pod'ы могут содержать несколько контейнеров, но вы должны ограничивать их количество, когда это возможно. Поскольку контейнеры масштабируются как единое целое, все контейнеры в паке должны масштабироваться вместе, независимо от их индивидуальных потребностей. Это приводит к потраченным впустую ресурсам и дорогому счету. Чтобы решить эту проблему, Pod'ы должны оставаться меньше на сколько это возможно, обычно вмещая только основной процесс и его тесно связанные вспомогательные контейнеры (эти вспомогательные контейнеры обычно называют Side-cars).
Deployments

Хотя в Kubernetes pod являются базовой единицей вычислений, они, как правило, не запускаются напрямую в кластере. Вместо этого pod обычно менеджится еще одним уровнем абстракции - deployment.
Основная цель юзать подход с deployment состоит в том, чтобы настроить, сколько реплик pod'а должно работать одновременно. Когда развертывание добавляется в кластер, оно автоматически деплоит требуемое количество pod'ов и отслеживает их. Если pod умирает, deployment автоматически пересоздает его.
Используя deployment, вам не нужно иметь дело с подами вручную. Вы можете просто объявить желаемое состояние системы, и оно будет управляться автоматически.
Ingress

Используя описанные выше концепции, вы можете создать кластер нодов и запустить деплоймент подов в кластере. Однако есть еще одна проблема, которую необходимо решить: разрешить внешний трафик вашему приложению. По умолчанию Kubernetes обеспечивает изоляцию между модулями и внешним миром. Если вы хотите общаться с сервисом, работающим в pod, вам нужно открыть канал для связи. Это называется Ingress.
Есть несколько способов добавить ingress в ваш кластер. Наиболее распространенными способами являются добавление либо ingress controller, либо LoadBalancer. Описание различий и что лучше выбрать выходит за рамки этой статьи, но вы должны держать в голове что вам нужно разобратся с доступом к сервису, если вы хотите работать с k8s.

Читайте также: